
✅ 01 객체지향 데이터베이스
📌 객체지향 데이터 모델 개요
- 객체 지향 개념에 기반한 데이터 모델
- 주요 개념: 객체, 객체 식별자(OID), 속성, 메서드, 클래스, 계층 구조, 상속, 복합 객체
- 다양한 응용 분야에 적합한 데이터 모델링 지원
- 의미 있는 관계 구조를 표현할 수 있는 강력한 설계 기능
- 특수 분야에서 주로 사용
📌 객체 (object)
- 현실 세계의 개체를 추상화한 것
- 객체는 고유 식별자 OID로 구별됨
- 속성(상태) + 메서드(행동)으로 구성
- 객체 간 참조는 OID를 통해 수행됨
📌 속성 (attribute)
- 관계형 DB의 속성과 유사한 개념
- 차이점:
- 관계형 DB: 단일 값만 가능
- 객체지향 DB: 복수 값, 사용자 정의 클래스 타입도 도메인으로 사용 가능
📌 메서드 (method)
- 객체에 수행할 수 있는 연산
- 속성 값을 조회, 수정, 삭제, 추가
- 프로그래밍 언어의 함수 개념과 유사
📌 메시지 (message)
- 객체에 접근하는 공용 인터페이스 역할
- 메서드 실행을 요청하는 방식으로 동작
- 예: 객체.메서드(값) 형태

📌 클래스 (class)
- 속성과 메서드를 공유하는 객체들의 그룹
- 객체 = 클래스의 인스턴스(instance)
- 클래스 내부에 객체 구조 + 메서드 정의 포함
📌 클래스 계층 (class hierarchy)
- 클래스의 세분화(specialization)로 계층 구조 형성
- IS-A 관계 기반
- 상위클래스 (superclass)
- 하위클래스 (subclass)

📌 상속 (inheritance)
- 상위 클래스의 속성과 메서드를
하위 클래스에 물려주는 개념
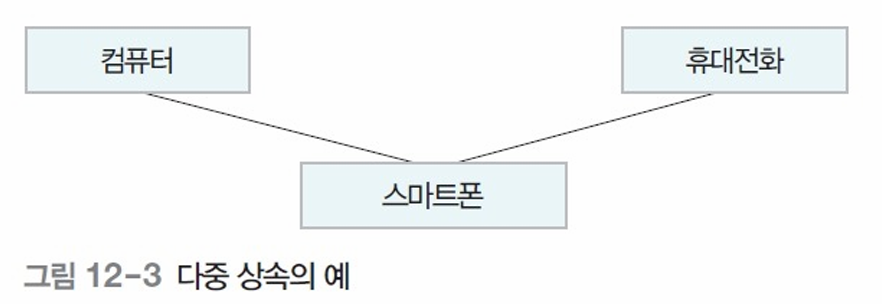
- 종류:
- 단일 상속: 하나의 상위클래스로부터 상속
- 다중 상속: 여러 상위클래스로부터 상속
📌 복합 객체 (composite object)
- 사용자 정의 클래스를 도메인으로 갖는 속성을 가진 객체
- 속성 값으로 다른 객체를 참조할 수 있음
- Is-Part-Of 관계를 표현할 때 사용
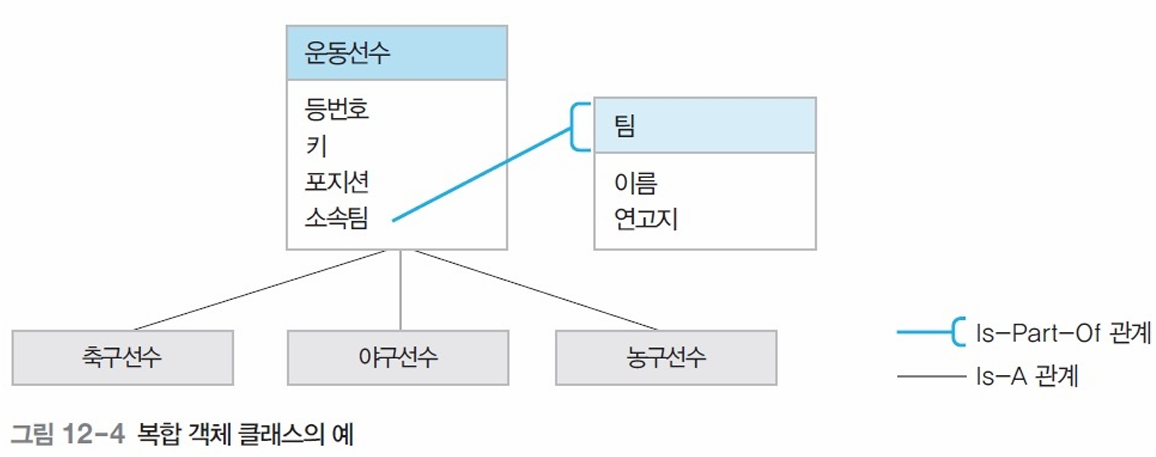
📌 객체지향 질의 모델
- 질의 대상: 클래스
- 질의 결과: 해당 클래스에 속하는 객체 집합
- 단일 오퍼랜드 질의: 한 클래스 또는 그 하위클래스 대상
- 다중 오퍼랜드 질의: 여러 클래스를 함께 질의
- 아직 완전한 표준 질의어는 없음
📌 예시 질의
- 운동선수 클래스에서
키 ≥ 180, 소속팀 연고지 = 서울인 객체를 검색하는 질의

✅ 02 객체관계 데이터베이스
📌 객체관계 데이터 모델
- 객체지향 개념 + 관계형 데이터 모델을 통합
- 지원 요소: 릴레이션, 객체, 클래스, 상속, 메서드, 캡슐화, 복합 객체 등
- **SQL3 (1999)**부터 객체지향 개념 지원
→ 객체관계 DB에 적용 가능 - 기본 SQL 기능 + 사용자 정의 타입, 객체 식별자, 메서드 등 객체지향 특성 포함
📌 객체지향 DB vs 객체관계 DB
구분 객체지향 DB 객체관계 DB
| 기반 철학 | OOP 기반에 DB 기능 추가 | 관계형 DB 기반에 OOP 개념 추가 |
| 목적 | 객체지향 프로그래밍과의 통합 | 관계형 모델 확장 |
| 특징 | OID, 캡슐화, 메서드 중심 | SQL 기반 확장성, 사용자 정의 타입 중심 |
✅ 03 분산 데이터베이스 시스템
📌 중앙 집중식 데이터베이스 시스템
- 데이터베이스 시스템을 물리적으로 한 장소에 설치하여 운영
📌 분산 데이터베이스 시스템 (Distributed DB)
- 물리적으로 분산된 데이터베이스를 네트워크로 연결
- 사용자는 마치 중앙 집중식 DB처럼 이용 가능

📌 주요 구성 요소
- 분산 처리기 (Distributed Processor)
- 각 지역 컴퓨터(Local Computer)
- 각자 자체 DBMS를 보유하여 관리
- 분산 데이터베이스 (Distributed Database)
- 지역별 자주 사용하는 데이터를 분산 저장
- 통신 네트워크
- 지역 간 자원 공유
- 효율적 구조 설계 필요
✅ 분산 데이터베이스 시스템의 목표
📌 분산 데이터 독립성
- 사용자는 DB가 분산되어 있음을 인식하지 못함
- → 분산 투명성을 통해 구현
📌 분산 투명성 (Distribution Transparency)
- 위치 투명성
- 사용자는 데이터 저장 위치를 몰라도 접근 가능
- 시스템이 자동으로 위치를 찾아 제공
- 중복 투명성
- 같은 데이터가 여러 지역에 있어도 하나처럼 보이게 함
- 단편화 투명성
- 데이터가 조각나서 분산되어 있어도
사용자에겐 하나로 보이게 처리
- 데이터가 조각나서 분산되어 있어도
- 병행 투명성
- 여러 트랜잭션이 동시에 수행돼도 일관성 유지
- 장애 투명성
- 일부 지역 시스템에 문제가 생겨도
전체 시스템은 정상 작동
- 일부 지역 시스템에 문제가 생겨도
✅ 데이터 저장 방식
📌 분산 저장 방식
- 중복 없이 분할 저장
- 중복 저장 방식 (더 일반적)

- 완전 중복: 동일 데이터 전체를 여러 지역에 저장
- 부분 중복: 일부 데이터만 중복 저장
✅ 단편화 (Fragmentation)
📌 개념
- 하나의 릴레이션을 더 작은 **조각(단편)**으로 나누어 저장
- 저장 공간과 관리 효율 향상

📌 단편화 방법
- 수평적 단편화
- 행(투플) 기준으로 나눔
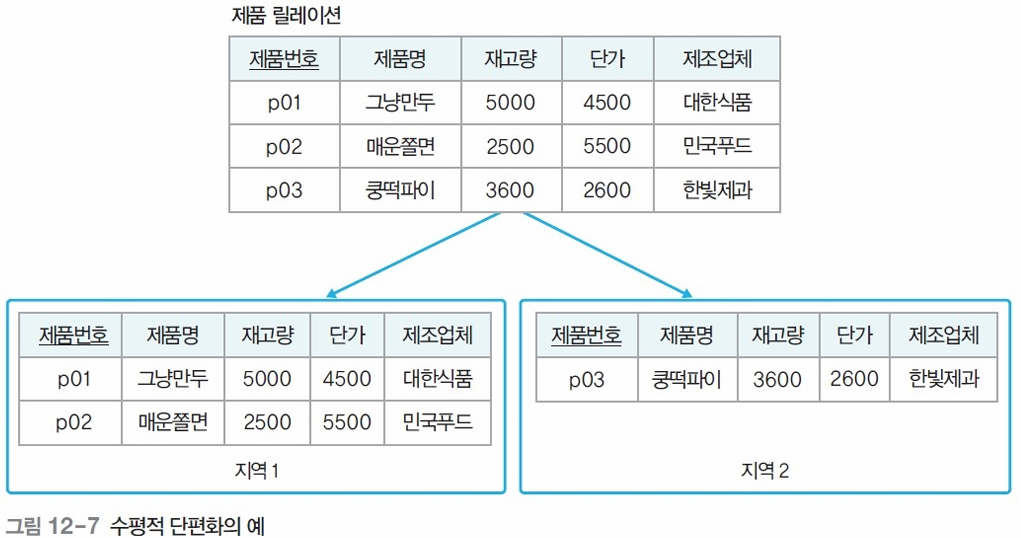
- 수직적 단편화
- 열(속성) 기준으로 나눔
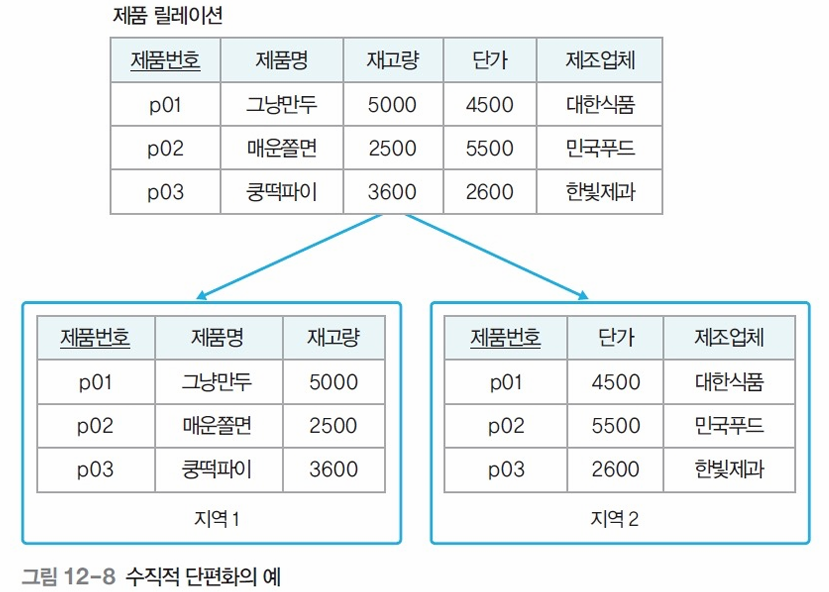
- 혼합 단편화
- 수평 + 수직 모두 적용
✅ 분산 투명성
🔹 단편화 투명성 (fragmentation transparency)
- 단편화된 데이터를 여러 지역에 나누어 저장하지만
사용자는 데이터가 단편화된 것을 인식할 수 없도록 하는 것
🔹 병행 투명성 (concurrency transparency)
- 분산데이터베이스와 관련된 트랜잭션들이 동시에 수행되더라도
결과는 항상 일관성을 유지하는 것
🔹 장애 투명성 (failure transparency)
- 특정지역 시스템에 문제가 발생하더라도
전체 시스템이 작업을 계속 수행할 수 있는 것

✅ 분산 DB의 스키마 구조
- 전역 개념 스키마 (Global Conceptual Schema)
- 전체 데이터 구조와 제약조건 정의 (분산은 고려 X)
- 단편화 스키마 (Fragmentation Schema)
- 전역 개념 스키마를 논리적으로 분할
- 할당 스키마 (Allocation Schema)
- 단편들을 물리적으로 저장할 지역을 지정
- 지역 스키마 (Local Schema)
- 지역별 저장 데이터 구조와 제약조건 정의
✅ 질의 처리 전략
- 디스크 접근 횟수
- 네트워크 전송 비용
- 병렬 처리에 따른 성능 향상
→ 이를 고려해 최적 전략을 선택
✅ 분산 데이터베이스 시스템의 장점
- 신뢰성과 가용성 증가
- 장애 발생 시에도 다른 지역 DB로 대체 가능
- 지역 자치성과 효율성 증가
- 지역 단위 관리 → 응답 시간 단축, 통신 비용 절감
- 확장성 증가
- 처리량 증가 시 → 새로운 지역에 DB 설치로 확장 가능
✅ 단점
- 설계 및 구축 비용이 높음
- 지역 간 관리 복잡 + 관리 비용 증가
- 중앙 집중식 시스템 대비
→ 통신/처리 비용 추가 발생
✅ 04 멀티미디어 데이터베이스 시스템
📌 미디어(media) & 멀티미디어 데이터
- 미디어: 문자, 숫자, 그래픽, 이미지, 비디오, 오디오 등의 데이터 타입
- 멀티미디어 데이터: 여러 미디어가 조합된 데이터
✅ 멀티미디어 데이터의 특성
1️⃣ 대용량 데이터
- 수 KB ~ 수십 MB 이상
- 압축 저장 필요
- 일반 데이터와 다른 구조로 별도 저장 공간 구성 필요
2️⃣ 검색 방법이 복잡함
- 설명 기반 검색 (description-based retrieval)
→ 키워드나 설명을 저장하여 검색
→ 예전 방식, 초기 시스템에 사용 - 내용 기반 검색 (content-based retrieval)
→ 실제 내용 기반 검색
→ 예: 손흥민이 포함된 비디오 검색
3️⃣ 복잡한 데이터 구조
- 구성 요소:
- 원시 데이터(raw): 이미지, 비디오 등 기본 데이터
- 등록 데이터(registration): 해상도, 색상 등 메타 정보
- 서술 데이터(description): 키워드, 설명 등 검색용 데이터
- 시공간적 관계 표현과 관리 기술 필요
✅ 멀티미디어 데이터베이스의 발전
🔹 관계형 데이터베이스 기반
- BLOB(Binary Large Object) 데이터 타입 사용
- 관계형 이론과 기법 활용 가능
- 단점: 시공간 특성, 통합 모델링, 복합 연산 표현이 부족
- 예: GENESIS, STAIRS
🔹 객체지향 데이터베이스 기반
- 객체와 클래스로 표현
- 추상화, 캡슐화, 상속 개념 사용
- 단점: 복잡한 모델링 요구를 완전히 충족하지 못함
- 예: ORION, MULTOS, MINOS
✅ 멀티미디어 DBMS의 구성
📌 시스템 요구사항
- DBMS의 기본 기능 + 멀티미디어 특성(대용량, 시공간성 등) 반영
- 적합한 관리 시스템이 중요
- 사용 예시: UniSQL, Oracle, Informix, O2, DB2 UDB
📌 구현 방식 비교
1. 파일 시스템 이용 방식
- 초기 방식
- 응용 프로그램에서 직접 파일로 저장 및 처리
- 단점:
- 개발 어려움
- DBMS 고급 기능 제공 어려움
2. 관계형 DBMS 이용 방식
- 텍스트: DB에 저장
- 이미지/비디오: 파일로 저장
- 예: GIS(지리정보시스템)
- 단점:
- 파일 저장분은 DB 고급 기능 활용 어려움
3. 확장된 관계형 DBMS 이용 방식
- 멀티미디어도 DB에 저장
- 예: BLOB 타입 활용
- 단점:
- SQL로 멀티미디어 표현/처리 어려움
4. 객체지향 DBMS 이용 방식
- 객체지향 개념 활용 (추상화, 상속 등)
- 다양한 멀티미디어 지원
- 단점: 전통 DBMS 기능(동시성 제어, 회복 등) 미비
✅ 멀티미디어 데이터의 질의
📌 특징
- 데이터 자체보다 포함된 객체, 설명, 키워드를 중심으로 질의
- 미디어 종류에 따라 다양한 질의 유형
📌 질의 유형
1. 텍스트 질의
- 키워드 기반 문서 검색
- 예: ‘한빛’과 ‘데이터베이스’를 포함한 문서
2. 비디오 질의
- 장면을 검색
- 예: ‘미녀’와 ‘야수’가 식사하는 장면
3. 이미지 질의
- 키워드 기반 검색
- 유사 이미지 검색
- 예: ‘개’가 포함된 이미지 / 제시 이미지와 유사한 이미지
4. 공간 질의
- 특정 위치 조건에 따른 검색
- 예: 한빛아카데미 5km 이내 식당 검색
- 예: 가장 가까운 식당 검색
✅ 질의 처리 기법
1. 매칭 (Matching)
- 저장된 데이터와 질의 데이터의 유사도 계산
2. 랭킹 (Ranking)
- 질의 조건과의 관련도 순서대로 정렬하여 출력
3. 필터링 (Filtering)
- 관련성이 낮은 데이터를 단계적으로 제거하면서 범위 축소
4. 인덱스 (Indexing)
- 인덱스 구조를 활용하여 질의 조건에 적합한 데이터 검색
✅ 05 기타 데이터베이스 응용 기술
📌 웹 데이터베이스 (Web Database)
🔹 필요성
- 다양한 웹 서비스에서 발생하는 대용량 데이터를 효율적으로 관리하기 위해
- 데이터베이스 시스템의 기능이 반드시 필요
🔹 개념
- 웹 서비스의 특성과
데이터베이스 시스템의 데이터 관리 기능을 통합한 구조
🔹 주요 구성 요소
- 미들웨어 (middleware)
- 웹 서비스와 DB 시스템을 연결하는 중간 계층
- → **데이터베이스 게이트웨이(database gateway)**라고도 함
- 구현 방식:
- 서버 확장 방식: DB 접근 프로그램을 웹 서버 쪽에 위치시킴
- 클라이언트 확장 방식: DB 접근 프로그램을 클라이언트 쪽에 위치시킴
📌 데이터 웨어하우스 (Data Warehouse)
🔹 개념
- 의사결정에 필요한 데이터를
DB에서 미리 추출, 변환, 통합해
읽기 전용으로 저장하는 데이터 저장소 - 핵심 목적:
→ 정확하고 빠르게 의사결정 데이터를 추출하기 위한 수단 - 다양한 DB로부터 데이터를 수집할 수 있음
→ 의사결정지원시스템(DSS) 구축에 활용
📌 데이터 웨어하우스의 특징
1️⃣ 주제 지향적 (subject-oriented)
- 일반 DB: 업무 처리 중심
- 데이터 웨어하우스: 의사 결정 중심 주제에 맞춘 데이터 유지
2️⃣ 통합성 (integrated)
- 다양한 DB로부터 데이터를 일관성 있게 통합 저장
3️⃣ 비소멸성 (nonvolatile)
- 일반 DB: 삽입, 삭제, 수정 잦음
- DW: 검색만 수행하는 읽기 전용 데이터 유지
4️⃣ 시간 가변성 (time-variant)
- 일반 DB: 현재 데이터만 유지
- DW: 과거 + 현재 데이터 모두 유지,
시점별 스냅샷(snapshot)으로 시간 흐름 분석 가능
'CS > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] CH13. 데이터 과학과 빅데이터 (2) | 2025.07.02 |
|---|---|
| [데이터베이스] 질의 최적화 (2) | 2025.07.02 |
| [데이터베이스] CH13. 데이터 과학과 빅데이터 (0) | 2025.06.16 |
| [데이터베이스] CH12. 데이터베이스 응용 기술 (0) | 2025.06.16 |
| [데이터베이스] 질의 최적화 (0) | 2025.06.16 |