1. 제곱정렬
정렬 알고리즘
- 원소들을 번호순이나 사전순서와 같이 일정한 순서대로 열거하는 알고리즘
- 아래 정렬 알고리즘들은 O(n^2)에 대해 동작
1.1 버블정렬(Bubble Sort)
void bubblesort(int A[],int N){
bool swapped = true;
while(swapped){
swapped = false;
for(int i=1; i<n; i++){ //바깥쪽 반복문의 i번째 실행에는 배열의 i번째로 큰 원소가 제자리로 가게 됨.
if(A[i]<A[i-1]){// --. 바깥쪽 반복분의 i번째 실행에는 안쪽 반복문을 N-i번만 실행해도 됨.
swap(A[i], A[i-1]);
swapped=true;
}
}
N--; //optimization
}
}
//배열이 정렬된 상태가 될 때까지
//[1.배열의 앞에서부터 순서대로 인접한 두 원소 비교
//2. 앞의 원소가 뒤의 원소보다 크다면 둘의 위치를 바꿔줌] 반복- 첫번째 실행에 가장 큰 원소 정렬
- i번째 실행에는 i번째로 가장 큰 원소 정렬
- 최악의 경우 N-1번째 실행에 N-1번째로 가장 큰 원소 정렬. 가장 작은 원소 또한 맨 앞에 위치 --> 바깥쪽 while문이 최대 N-1번 실행 -- 시작 배열이 역순으로 정렬되어 있을 때 해당
- 안쪽반복문에 대한 최악의 경우: 바깥쪽 반복문의 모든 i번째 실행에서 i번째로 가장 큰 원소를 정렬하기 위해 N-i번의 비교연산을 해야 하는 경우 - 시작배열이 역순으로 정렬되어 있을 때
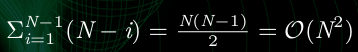
1.2 선택정렬(Selection Sort)
void selectionsort(int A[], int N)
{
for(int i=0; i<N; i++{
int min_pos=i;
for(int j=i+1; j<N; j++){
if(A[min_pos]>A[j]){
min_pos=j;
}
}
swap(A[min_pos], A[i]);
}
}
- N번반복, i번째 실행에는 다음과 같은 동작
- 현재 배열의 i번째에서 N번째 원소중 가장 작은 원소 찾기
- 선택된 가장 작은 원소와 i번째 원소의 위치 바꿈
- 이중 for문 -> 시간복잡도 : O(N^2)
1.3 삽입정렬(Insertion Sort)
void insertionsort(int A[], int N)
{
for(int i=1, i<N; i++){
int j=i;
while(j>0 && A[j]<A[j-1]){
swap(A[j], A[j-1]);
j--;
}
}
}- i번째 실행에 배열의 맨 앞에 길이 i의 정렬된 부분배열을 유지하며 그 안에 i+1번째 원소를 올바른 위치에 삽입하는 형태로 작동
- 시간복잡도 : O(N^2)
2. 선형자료구조
- 원소들이 순서대로 선형으로 나열되어있는 자료구조 (ex. 배열)
2.1 큐(Queue)

- 줄을 서는 구조
- 2가지 연산 지원
- Enqueue - 큐의 맨 뒤에 원소 삽입
- Dequeue - 큐의 가장 앞의 원소를 큐에서 빼냄
- FIFO
- 두 연산 모두 O(1)의 시간복잡도 가짐
2.2 스택(Stack)

- 2가지 연산 지원
- Push- 스택의 맨 뒤에 원소 삽입
- Pop - 스택의 가장 뒤 원소를 스택에서 빼냄
- LIFO
- 두 연산 모두 O(1)의 시간복잡도 가짐
2.3 덱(Deque)

- queue와 stack이 합쳐진 구조.
- 자료구조의 맨 앞과 맨 뒤에서 삽입삭제를 모두 지원
- 4가지 연산 모두 O(1)의 시간복잡도 가짐
연결리스트(Linked List)
- 임의의 위치에서 삽입과 삭제를 O(1)의 시간복잡도에 지원
- 이를 위해 각 원소는 값뿐만 아니라 다음 원소의 위치와 이전 원소의 위치를 저장
- 원소가 삽입/삭제될 때 다음 원소와 이전 원소의 위치에 대한 정보를 수정하는 방식으로 빠른 삽입과 삭제를 지원
- BUT 원소를 삽입/삭제할 위치를 미리 알고 있을 때 삽입과 삭제 자체가 빠른 것. 위치를 찾는 탐색과정은 O(N)
[삽입]

- 두 원소 a, b 사이에 새 원소 x를 삽입하는 과정 가정
- 새로운 원소에 대해 이전원소를 a로 다음원소를 b로 설정
- a의 다음 원소를 x로 설정
- b의 이전 원소를 x로 설정
- 실제 구현에서 위 세 과정은 단순히 구조체나 변수의 값을 조작하는 과정으로 완료. 총 시간 복잡도는 O(1).
[삭제]
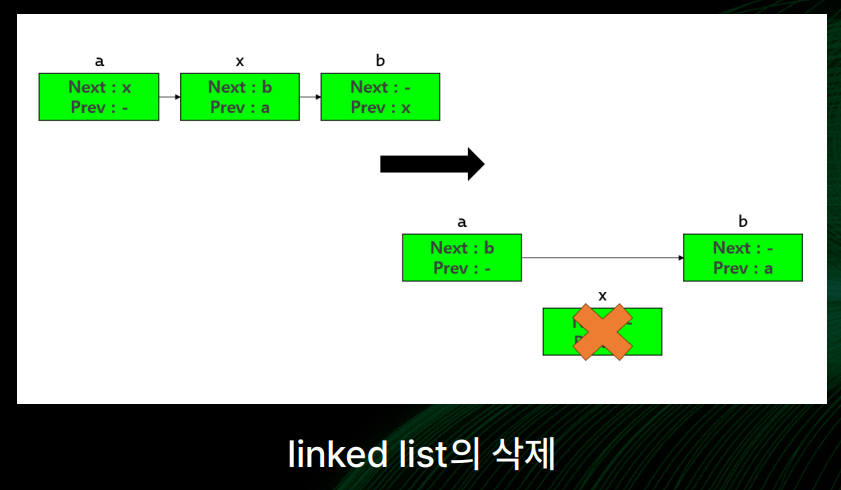
- 두 원소 a, b 사이에 새 원소 x를 삽입하는 과정 가정
- a의 다음 원소를 b로 설정
- b의 이전 원소를 a로 설정
- x 삭제
- 단순히 구조체나 변수값을 조작하는 과정으로 완료 -> 총 시간복잡도 : O(1)
STL이란?
- STandard Library 의 줄임말
- C++이 자체적으로 제공하는 라이브러리 함수, 클래스, 템플릿 등
- 자료구조들이 전부 C++ STL에 미리 구현돼있음
- STL에서 제공하는 자료구조 사용을 위해서는 적절한 헤더를 include해줘야 함
- 전부 std namespace에 해당
std::vector
#include <iostream>
#include <vector>
using namespace std;
int main(){
vector <int>v={1, 2, 3, 4};
v.push_back(5);
cout << v.size() << '\n'; //5
v.pop_back();
cout << v.size() << '\n'; //4- 인덱싱이나 값의 접근 등은 일반적 배열과 유사
- push_back을 사용해 맨 뒤에 새로운 원소 삽입 가능. O(1)의 시간복잡도 가짐
- pop_back을 사용해 맨 뒤 원소 삭제 가능.
//배열의 가장 중요한 특징 중 하나: 연속된 공간 사용
v.insert(v.begin() + 1, 6);
for(int i=0; i<v.size(); i++){
cout << v[i] << ' ';
} // 1 6 2 3 4
cout << '\n';
v.erase(v.begin() + 1);
for(int i=0; i<v.size(); i++){
cout << v[i] << ' ';
} // 1 2 3 4
cout << '\n';- 연속성을 유지하기 위해 새로운 원소를 임의 위치에 삽입할 때는 그 위치 뒤에 있는 원소들을 한 칸씩 밀어내야 함. 삭제할 때도 마찬가지로 한 칸씩 앞당겨야 함.
- 따라서 임의 위치에 삭제와 삽입이 insert와 erase를 통해 가능 but 최악의 경우 O(N)의 시간복잡도 가짐
v.clear(); // 모든 원소 삭제. 시간복잡도: O(N)
cout << v.size() << '\n'; //0
cout << v.empty() << '\n'; //- empty : vector가 비어있다면 true, 비어있지 않다면 false 반환. 해당 함수는 vector, queue, stack, deque, list 전부 있으며 동일하게 작동.
- size도 마찬가지로 이 글에 등장하는 모든 자료구조에서 동일하게 작동
std::vector
#include <iostream>
#include <vector>
using namespace std;
int main(){
vector<int>v(5);
cout << v.size() << '\n'; //5
vector<int>filled_v(5,1);
for(int i=0; i<5; i++){
cout << filled_v[i] << ' ';
} // 1 1 1 1 1
}- 초기 크기를 인자로 넘겨주는 선언방식
- 크기와 함께 두 번째 인자로 vector을 채울 값을 설정하는 것 또한 가능
std::queue
STL에서 제공하는 queue
#include <iostream>
#include <queue>
using namespace std;
int main(){
queue<int>q;
q.push(1); q.push(2); q.push(3)
;
cout << q.size() << '\n'; //3
cout << q.front() << '\n'; //1
q.pop();
cout << q.front() << '\n'; //2
cout << q.size() << '\n'; //2
}- push로 enqueue, pop으로 dequeue.
- front는 queue의 맨앞 값을 반환
std::stack
STL에서 제공하는 stack
#include <iostream>
#include <stack>
using namespace std;
int main(){
stack<int>s;
s.push(1); s.push(2); s.push(3);
;
cout << s.size() << '\n'; //3
cout << s.top() << '\n'; //3
s.pop();
cout << s.top() << '\n'; //2
cout << s.size() << '\n'; //2- push로 삽입, pop으로 삭제
- top은 stack의 맨위/뒤에 있는 값 반환
std::deque
#include <iostream>
#include <deque>
using namespace std;
int main(){
deque<int>d;
d.push_back(2);d.push_front(1);
d.push_back(3); d.push_back(4);
cout << d.size() << '\n'; //4
d.pop_front();
d.pop_back();
for(int i=0; i<d.size(); i++){
cout << d[i] << ' ';
} //2 3
cout << '\n';
cout << d.front() << ' '<< d.back() << '\n'; // 2 3- push와 pop 뒤에 _front 또는 _back을 붙여서 삽입/삭제를 앞에 할건지 뒤에 할건지 구분
- 배열과 같이 인덱싱 지원 -> 임의 원소 접근이 O(1)
- front와 back은 각각 deque의 맨 앞에 있는 원소, 맨 뒤에 있는 원소 반환
std::list
//STL에서 제공하는 linked list
#include <iostream>
#include <list>
using namespace std;
int main(){
list<int>li;
li.push_back(2);
li.push_back(3);
li.push_front(1);
for(auto i=li.begin(); i!=li.end(); i++){
cout << *i < ' ';
} //1 2 3
cout << '\n';
li.pop_back();
li.pop_front();
cout << li.size(); //1
}- 임의 위치에 삽입/삭제 지원하는 자료구조 -> 맨앞, 맨뒤에도 삽입/삭제를 deque와 같이 지원
- 값 출력하는 반복문이 좀 특이 - list는 인덱싱 지원 x, 값 접근 위해 iterator 사용
- 메모리가 비연속적이라 탐색이 O(N)의 시간복잡도 가짐
#include <iostream>
#include <vector>
using namespace std;
int main(){
vector<int>v={1,2,3,4,5};
cout << *(v.begin()) << '\n'; // 1
cout << *(v.begin()+3) << '\n'; //4
vector<int>::iterator it1 = v.begin();
itl++; itl++;
cout << *itl << '\n'; //3
auto it2 = v.begin();
it2++; it2++;
cout << *it2 << '\n'; //3- 간단히 iterator은 자료구조 내에서 어떤 값을 가리키는 위치
- 실제 값을 접근할 때는 *(iterator)의 형태로 접근
- ++과 --을 사용해 앞 또는 뒤로 이동시킬 수 있음.
- begin: 자료구조의 맨 앞 위치에 해당하는 iterator
- end: 자료구조의 마지막 원소 다음 위치에 해당하는 iterator(정말로 자료구조의 끝마침을 나타냄)
- 선언하는 문법이 복잡해서 일반적으로 auto라는 키워드로 대체
#include <iostream>
#include <list>
using namespace std;
int main(){
list<int>li={1,2,3,4,5};
auto it=li.begin();
it++; it++;
li.insert(it,6);
for(auto i : li){
cout << i << ' ';
} // 1 2 6 3 4 5
}
- std::list에서 값의 접근은 iterator 사용
- 이는 삽입과 삭제에도 해당, 이 경우 삽입할 위치, 삭제할 위치 나타내는 데 사용
- insert의 첫 번째 인자로 iterator을, 두 번째 인자로 값을 사용
- iterator가 가리키는 위치 앞에 새 원소가 들어가게 됨
- insert함수의 반환값은 삽입된 원소를 가리키는 iterator.
#include <iostream>
#include <list>
using namespace std;
int main(){
list<int>li={1,2,3,4,5};
auto it =li.begin();
it++; it++;
it = li.erase(it);
for(auto i : li){
cout << i << ' ';
} // 1 2 4 5
cout << '\n';
cout << *it << '\n'; //4
li.erase(li.begin(), li.end());
li.size(); //0
}- erase함수의 인자로 iterator가 들어가며 iterator가 가리키는 위치의 원소가 삭제됨
- 두 번째 인자로 iterator을 넣어 두 iterator 사이에 위치한 모든 원소를 삭제하는 것도 가능
- erase함수의 반환값은 삭제된 마지막 원소 다음 원소를 가리키는 itreator
std::pair
두 값을 묶어서 저장하게 해주는 pair
#include <iostream>
#include <string>
#include <utility> //utility 헤더에 포함
using namespace std;
int main(){
pair<int, string>p1; //묶는 값들이 같은 자료형이 아니어도 됨
//pair 2개를 pair로 묶거나 pair의 vector을 선언하는 등 다양한 활용 가능
p1=make_pair(25,"Sinchon");
cout << p1.first << ' '<<p1.second << '\n'; //25 Sinchon //first로 첫번째 값을, second로 두번째 값에 접근 가능
pair<int,int>p2={3,5};
cout << p2.first +p2.secont; //8
}
std::tuple
다른 자료형의 두 개보다 많은 값을 묶어서 저장하게 해 주는 tuple
#include <iostream>
#include <string>
#include <tuple>
using namespace std;
int main(){
tuple<int, string, string> t1 = make_tuple(25, "Sinchon","W");
cout << get<0>(t1) << ' '<<get<1>(t1) << ' ' <<get <2>(t1) << '\n'; // 25 Sinchon W
tuple<int,int>t2 = {3,5};
auto[x1,x2]=t2;
cout << x1 << ' '<<x2; //0 6
}- tuple 헤더에 포함
- 특이한 문법 많이 사용
'언어 > C++' 카테고리의 다른 글
| [C++] ICPC 25W 6회차 - 재귀 및 DnC(분할정복) (0) | 2025.02.13 |
|---|---|
| [C++] ICPC 25W 5회차 - 완전탐색, 이분탐색 (0) | 2025.02.11 |
| [C++] ICPC 25W 4회차 - 누적합, 투포인터 (1) | 2025.02.04 |
| [C++] ICPC 25W 3회차 - 정렬, 수학 (2) | 2025.01.31 |
| [C++] ICPC 25W 1회차 - 알고리즘과 시간복잡도 (3) | 2025.01.25 |