- 그래프: 정점의 집합과 간선의 집합으로 정의되는 이산수학의 추상적 구조
- 정점: 어떠한 상태 or 위치 표현
- 간선: 정점 사이의 관계나 연결성 표현
- ex) 지하철 노선도
- 그래프의 종류
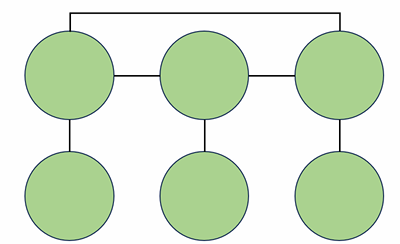
- 모든 간선이 방향이 정해져 있지 않은 그래프
- 하나의 간선으로 양방향으로 이동 가능
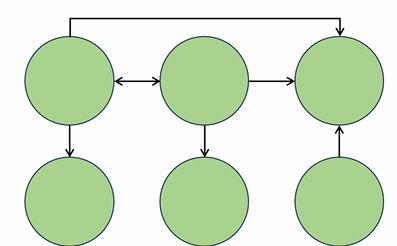
- 방향이 정해져 있는 간선이 있는 그래프
- 양방향 간선도 사실 방향이 있는 간선 두 개로 나눠서 생각해볼 수 있음
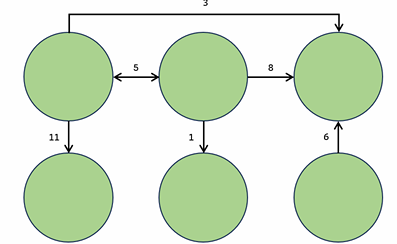
- 간선에 가중치가 있는 그래프
- 가중치: 간선 이용하는 비용
- 일상예시: 지도 상의 여러 위치를 정점으로, 정점들 사이의 경로를 간선으로 잡으면 경로의 소요시간을 가중치로 모델링 가능
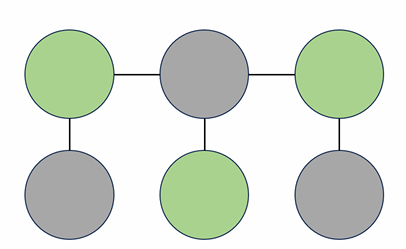
- 같은 집합의 두 정점이 간선으로 이어지지 않게끔 정점들을 두 집합으로 나눌 수 있는 그래프
- 초록색 정점들을 하나의 집합으로 묶고 회색 정점들을 하나의 집합으로 묶을 수 있다.
- 판별법
- 정점 하나를 시작점으로 잡고 정점을 초록색으로 칠함
- 그 후 시작점에 인접한 모든 정점들을 회색으로 칠함
- 회색으로 칠한 정점들에 인접한 모든 정점들을 초록색으로 칠해주고, 다시 초록색으로 칠해진 정점들에 인접한 정점들을 회색으로 칠해주는 과정 반복
- 여기서 모순 발생하면 이분그래프 X
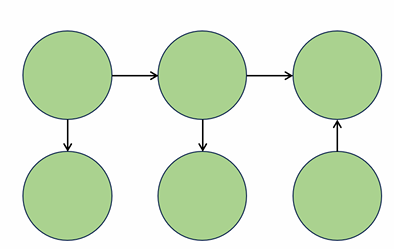
- Directed Acyclic Graph(방향 비순환 그래프). 방향그래프이면서 사이클이 없는 그래프 의미
2. 그래프의 표현방식(코드로)
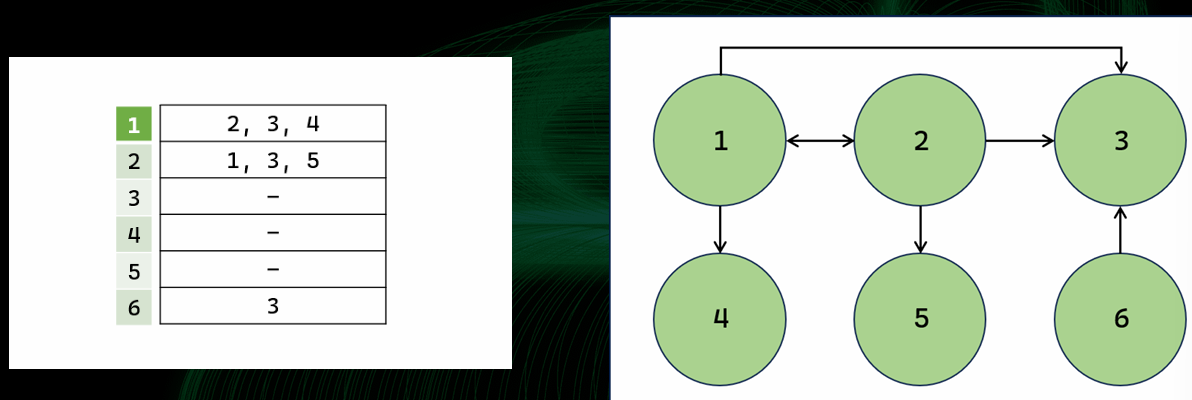
1. 인접행렬
- N개의 정점이 있는 그래프에 대해 N*N 크기의 이차원 배열 만들기
- 정점 u에서 정점 v로 가는 간선이 있다면 u행 v열에 위치한 칸을 1로 표시, 없다면 0으로 표시

int graph[305][305];
int u,v;
cin >> u >> v;
graph[u][v]=1;- 단순히 2차원 배열을 선언해주면 된다.
- 정점 u에서 v로 가는 간선을 추가하기 위해서 u행 v열에 해당하는 위치를 1로 설정해주면 됨.
- 단점 : 간선의 개수가 N*N보다 적어도 무조건 N^2의 메모리를 사용해야 한다.
2. 인접리스트
- 각 정점으로부터 간선으로 연결돼있는 정점들을 각각의 리스트로 표현하는 방식
- u번 정점에서 v번 정점으로 가는 간선이 있다면 u번 정점에 해당하는 리스트에 v 추가
vector<int> edges[200005];
int u,v;
cin >> u >> v;
edges[u].push_back(v);- 정점 개수만큼 정수형 vector로 이루어진 배열 만들기 -> edges[u]로 u번 정점에 해당하는 리스트에 접근가능
- 정점 u에서 정점 v로 가는 간선을 추가하기 위해서 u번 정점에 해당하는 vector에 v를 넣어주면 된다.
- 단점: 어떤 두 정점이 간선으로 연결돼있는지 확인하는 게 느림
3. 간선리스트
vector<pair<int,int>> edges;
int u,v;
cin >> u >> v;
edges.push_back({u,v});- 이름 그대로 간선을 리스트로 모아두면 끝.
- 가장 단순한 표현법, 코드로는 단순히 입력받은 간선을 pair로 묶어서 배열에 저장.
3. 트리

- 사이클이 없는 연결되어있는(임의의 두 정점 사이 경로가 존재하는) 무방향그래프
- N개의 정점으로 이루어진 트리는 항상 N-1개의 간선 가짐
- 트리에서 두 정점 사이 경로는 유일
Rooted Tree
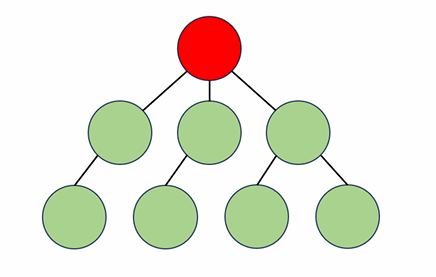
- 트리의 가장 '높은' 정점: 루트
- 어떤 정점의 부모정점: 그 정점에서 루트로 가는 경로에 있는 점 중 가장 가까운 정점
- 루트는 부모가 없다.
- 정점 x를 부모로 하는 정점 y가 있다면 y를 x의 자식정점이라고 한다.
- 자식정점이 없는 정점은 리프라고 한다.
- 어떤 정점의 높이 : 그 정점에서 리프로 내려가는 경로중 가장 긴 경로의 길이
- 트리의 높이: 루트의 높이
- 트리의 어떤 정점 x와 그 정점의 후손(그 정점에서 리프로 가는 길에 있는 모든 정점들)로만 이루어진 트리 : 'x를 루트로 하는 서브트리'
이진트리

- 모든 정점의 자식 정점 개수가 2 이하인 트리 : 이진트리
- 비슷하게 모든 정점의 자식 정점 개수가 k 이하인 트리 : k-ary tree
균형잡힌 이진트리
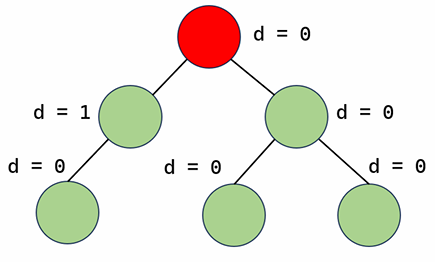
- 이진트리 중 다음 조건을 만족하는 경우
- 모든 정점에 대해 왼쪽 자식을 루트로 하는 서브트리의 높이와 오른쪽 자식을 루트로 하는 서브트리의 높이의 차이가 1 이하인 이진트리
- 가장 중요한 성질 : 균형잡힌 이진트리의 높이는 정점 개수 N에 대해 O(logN)
이진탐색트리
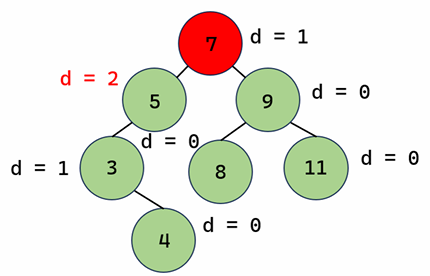
- 정점에 저장된 값이 x라고 했을 때 x보다 작은 값들은 전부 왼쪽 자식을 루트로 하는 서브트리에 속하게 됨
- x보다 큰 값들은 전부 오른쪽 자식을 루트로 하는 서브트리에 속하게 됨
- 어떤 값을 찾을 때 : 루트에서 시작해서 지금 보는 정점에 저장된 값보다 찾는 값이 작다면 왼쪽, 더 크다면 오른쪽으로 이동하기
균형잡힌 이진탐색트리(BBST)
- 실제로 이진탐색의 O(logN)이라는 매우 효율적인 시간 복잡도를 유지하기 위해 균형을 잡은 이진탐색트리
- 삽입, 탐색, 삭제를 전부 O(logN)시간에 지원
굉장히 유용한 STL : set과 map
1. std::set
- 정렬되어 있는 집합
#include <iostream>
#include <set>
using namespace std;
int main(){
multiset<int> st;
multiset<int>::iterator it;
for(int i=1; i<=5; i++) st.
insert(10);
st.erase(10)
// set:
for(int i=1; i<=5; i++) st.
insert(10);
st.erase(st.find(10));
//set: 10 10 10 10
}- set 헤더를 include 해 줘야 한다.
- 같은 값을 여러 번 넣어도 한 번만 들어간다.
- insert로 값 삽입
- erase로 값 삭제 - iterator를 인자로 넣어서 그 위치에 해당하는 값을 삭제하는 것 또한 가능
- find로 값 찾기. 반환값 : 해당 값이 존재할 경우 그 위치에 해당하는 iterator. 존재하지 않을 경우 .end()
2. std::multiset
#include <iostream>
#include <set>
using namespace std;
int main(){
multiset<int> st;
for(int i=1; i<=5; i++) st.
insert(10);
st.erase(10);
//set:
for(int i=1; i<=5; i++) st.
insert(10);
st.erase(st.find(10));
//set: 10 10 10 10
for(auto i=st.begin(); i!=st.
end(); i++){
cout << *i << ' ';
}
}
- 같은 값을 여러 번 넣을 수 있다.
- insert로 값 삽입
- erase로 값 삭제
- 값 자체를 인자로 넣을 경우 그 값을 전부 삭제 -> 값을 하나만 지우고 싶은 경우 erase(st.find(x))와 같이 iterator를 사용해야 한다.
3. std::map
#include <iostream>
#include <map>
#include <utility>
using namespace std;
int main(){
//추가
map<string,int>mp;
mp.insert(pair<string,int>("sinchon",25));
mp["W"]=2;
//접근
int x=mp["sinchon"];
int y=mp.at("sinchon");
//삭제
mp.erase("sinchon");
mp.erase(mp.find("W"));
}- map 헤더를 include 해야한다.
- map<{key의자료형},{값의자료형}>의 형태로 선언
- at이나 [key]를 통해 저장돼있는 값을 접근 또는 수정 가능
- [key]에 새로운 값 지정 or insert로 값 삽입. insert로 삽입하는 값은 pair(key,value)여야 하며 같은 key 가진 값이 이미 존재해서는 안된다.
- erase의 인자로 key를 넣어서 값 삭제. iterator를 인자로 넣어서 그 위치에 해당하는 값을 삭제하는 것 또한 가능
- find로 값 찾기. 반환값은 해당 key가 존재할 경우 그 위치에 해당하는 iterator이며 존재하지 않을 경우 .end()
'언어 > C++' 카테고리의 다른 글
| [C++] 알튜비튜 2주차 - 스택, 큐, 덱 (0) | 2025.02.27 |
|---|---|
| [C++] ICPC 25W 9회차 - dp (1) | 2025.02.23 |
| [C++] ICPC 25W 6회차 - 재귀 및 DnC(분할정복) (0) | 2025.02.13 |
| [C++] ICPC 25W 5회차 - 완전탐색, 이분탐색 (0) | 2025.02.11 |
| [C++] ICPC 25W 4회차 - 누적합, 투포인터 (1) | 2025.02.04 |