4.7 Baseline 모델
실질적인 머신러닝 파이프라인 구축하기(Baseline 모델 구축)
순서 : 데이터 전처리 -> 피처 엔지니어링 -> 학습 모델(LightGBM) 정의 -> 모델 학습 및 교차 검증 평가 -> 테스트 데이터 예측 및 캐글 업로드
머신 러닝 파이프라인은 일련의 상호 연결된 데이터 처리 및 모델링 단계로서, 머신 러닝 모델을 구축, 학습, 평가 및 배포하는 프로세스를 자동화, 표준화 및 간소화하도록 설계되었습니다. 머신 러닝 시스템 개발 및 생산화의 중요한 구성 요소인 머신 러닝 파이프라인은 데이터 과학자와 데이터 엔지니어가 엔드투엔드 머신 러닝 프로세스의 복잡성을 관리하고, 다양한 애플리케이션을 위한 정확하고 확장 가능한 솔루션을 개발할 수 있도록 지원합니다.
머신 러닝 기술은 빠른 속도로 발전하고 있지만, 머신 러닝 및 딥 러닝 모델을 구축하고 배포하는 과정은 몇 가지 주요 단계로 구분할 수 있습니다.
- 데이터 수집: 이 초기 단계에서는 데이터베이스, API 또는 파일과 같은 다양한 데이터 소스에서 새 데이터를 수집합니다. 이 데이터 수집에는 유용하게 사용하기 위해 사전 처리를 거쳐야 할 수도 있는 원시 데이터가 포함되는 경우가 많습니다.
- 데이터 사전 처리: 이 단계에는 모델링을 위한 입력 데이터 정리, 변환 및 준비가 포함됩니다. 일반적인 사전 처리 단계에서는 결측값 처리, 범주형 변수 인코딩, 숫자 피처 스케일링, 데이터를 학습 및 테스트 세트로 분할하는 작업이 수행됩니다.
- 기능 엔지니어링: 기능 엔지니어링은 모델의 예측력을 개선할 수 있는 새로운 기능을 만들거나, 데이터에서 관련 기능을 선택하는 프로세스입니다. 이 단계에서는 종종 도메인에 대한 지식과 창의력이 필요합니다.
- 모델 선택: 이 단계에서는 문제 유형(예: 분류, 회귀), 데이터 특성 및 성능 요구 사항에 따라 알맞은 머신 러닝 알고리즘을 선택합니다. 하이퍼 매개 변수 조정을 고려할 수도 있습니다.
- 모델 학습: 선택된 모델이 선택된 알고리즘을 사용하여 학습 데이터 세트에서 학습합니다. 학습 데이터 내의 기본 패턴과 관계를 학습하는 작업이 여기에 포함됩니다. 새로운 모델을 학습시키지 않고 미리 학습된 모델을 사용할 수도 있습니다.
- 모델 평가: 학습 후에는 별도의 테스트 데이터 세트를 사용하거나 교차 검증을 통해 모델의 성능을 평가합니다. 특정 문제에 따라 다르지만 일반적인 평가 메트릭에는 정확도, 정밀도, 재현율, F1 점수, 평균 제곱 오차 등이 포함될 수 있습니다.
- 모델 배포: 만족스러운 모델을 개발하고 평가한 후에는 프로덕션 환경에 배포하여 보이지 않는 새로운 데이터에 대한 예측을 수행할 수 있습니다. 배포에는 API 생성 및 다른 시스템과의 통합이 포함될 수 있습니다.
- 모니터링 및 유지 관리: 배포 후에는 모델의 성능을 지속적으로 모니터링하고 변화하는 데이터 패턴에 적응하기 위해 필요한 경우 모델을 재교육하는 것이 중요합니다. 이 단계를 통해 모델이 실제 환경에서 정확하고 신뢰할 수 있는 상태를 유지할 수 있습니다. 출처 : https://www.ibm.com/kr-ko/topics/machine-learning-pipeline
머신 러닝 파이프라인이란 무엇인가요? | IBM
머신 러닝(ML) 파이프라인은 ML 모델 작업 프로세스를 간소화하기 위해 상호 연결된 일련의 데이터 처리 및 모델링 단계입니다.
www.ibm.com
1. 데이터 전처리
- train.csv 라는 하나의 훈련데이터 파일, test.csv 라는 하나의 테스트 데이터파일 제공.
데이터셋을 나누는 이유 : test set과 중간고사를 보기 전에 출제될 시험 문제와 정답을 미리 알려주고 시험을 본다면 어떨까? 시험문제와 정답만 외우면 100점을 맞을 것이다. 머신러닝도 이와 마찬가지이다. 도미와 빙어의 데이터와 타깃을 주고 훈련한 다음, 같은 데이터로 테스트한다면 모두 맞히는 것이 당연하다. 연습 문제와 시험문제가 달라야 올바르게 학생의 능력을 평가할 수 있듯이 머신러닝 알고리즘의 성능을 제대로 평가하려면 훈련 데이터와 평가에 사용할 데이터가 각각 달라야 한다. 이렇게 하는 가장 간단한 방법은 평가를 위해 또 다른 데이터를 준비하거나 이미 준비된 데이터 중에서 일부를 떼어 내어 활용하는 것이다. 일반적으로 후자의 경우가 많다. 평가에 사용하는 데이터를 테스트 세트 test set , 훈련에 사용되는 데이터를 훈련세트 train set라고 부른다. (출처 : 혼자 공부하는 머신러닝 딥러닝)
- 탐색적 데이터분석 과정을 통해 확인했듯이, 변수들은 모두 익명화되어있고, 값들은 숫자로 치환돼있다. + 범주형 변수도 이미 숫자로 치환돼있다. --> 데이터 전처리 필요 x
- 한 개 이상의 csv 파일이 훈련데이터파일이 제공될경우, 데이터 전처리 과정을 통해 하나의 거대한 데이터 프레임으로 합치는 작업 필요.
- 훈련데이터 안에 문자열 데이터가 존재하거나, 수치형 데이터여야 할 값 ex)나이, 생년월일 이 정상적인 수치형 데이터로 표현되지 않을 경우 데이터 전처리 과정을 통해 올바른 데이터 타입과 값을 갖도록 수정해야 한다.
먼소리야?
CSV 파일은 일종의 데이터 표라고 보면 돼. 파일 하나하나가 각각 표처럼 되어 있고, 이걸 파이썬에서는 보통 **데이터프레임(DataFrame)**으로 불러오지.
만약 여러 CSV 파일이 있다면, 이 데이터를 한 곳에 모아서 분석하기 쉽게 하나의 거대한 데이터프레임으로 합쳐야 하는 상황이 있어.
2. 피처 엔지니어링
- 테이블형 데이터가 주어지는 경진대회의 묘미 (테이블형에서만 가능?)
피처 엔지니어링은 테이블형 데이터뿐만 아니라 다양한 데이터 유형에서도 가능해. 데이터를 모델 학습에 적합한 형태로 변환하거나, 새로운 유의미한 특징을 생성하는 작업이기 때문에, 텍스트, 이미지, 음성 데이터 등에서도 활용돼. 각각의 데이터 유형별로 피처 엔지니어링 방법은 다르지만 본질은 같아.
- 완전히 익명화된 데이터로도 다양한 피처 엔지니어링 수행 가능 - 실제 변수 이름을 알 수 없기에 초기에 방향성 찾기 어려움 BUT 탐색적 데이터 분석을 통해 얻은 통찰을 피처 엔지니어링에 활용 -> 유의미한 파생변수 생성 가능 (어떤 식으로? 예시 찾기)
익명화된 데이터에서도 충분히 피처 엔지니어링이 가능해. 변수 이름을 모르더라도 데이터를 탐색적 데이터 분석(EDA) 하면서 숨겨진 패턴과 상관관계를 찾을 수 있어. 이를 활용해서 유의미한 파생 변수를 생성할 수 있지.
예시: 익명화 데이터에서 파생 변수 생성
- 기초 통계 분석:
- 변수 간의 상관관계 확인.
- 각 변수의 평균, 분산, 왜도/첨도 확인.
- 분포 분석을 통해 데이터 특성 파악.
- 두 변수 A와 B가 강한 상관관계를 가진다면 A * B, A / B와 같은 파생 변수 생성 가능.
- 시간 데이터가 포함된 경우:
- 특정 변수가 날짜나 시간 정보를 나타낸다고 가정하고, 연/월/일, 주말 여부, 계절 정보 등을 파생.
- 익명_변수1이 시간이라면, 시간대별(0~6: 야간, 6~12: 오전, ...), 주말 여부, 월별 특징 추가.
- 범주형 변수 처리:
- 변수 내 유니크 값 수를 파악해 범주형 변수 여부를 추정.
- 범주별로 집계 데이터 생성 (예: 그룹별 평균, 합계 등).
- 익명_변수2가 범주형 변수라면, 범주별 평균값이나 비율 파생 가능.
- (피처 엔지니어링 자세한 설명과 예시 넣기)
피처 엔지니어링은 모델 학습에 입력할 데이터를 더 풍성하고 가치 있게 만드는 작업입니다. “Garbage in, garbage out”이라는 말이 있는데, 쓰레기 같은 데이터가 들어가면 쓰레기 같은 결과가 나온다는 의미입니다. 반대로 생각하면, 데이터가 좋을수록 더 좋은 결과를 얻을 수도 있습니다. 그래서 피처 엔지니어링은 머신러닝 프로세스에서 가장 중요한 과정이라고 해도 무리가 없으며, 그만큼 많은 시간과 노력을 들여야 합니다. 방법 또한 무궁무진하다.


3가지 기초적인 피쳐 엔지니어링 수행
- 결측값의 개수를 나타내는 missing 변수
- 이진 변수들의 총합
- Target Encoding 파생변수
#파생변수 01 : 결측값을 의미하는 "1"의 개수 세기
train['missing']=(train==-1).sum(axis=1).astype(float)
test['missing']=(test==-1).sum(axis=1).astype(float)
#파생변수 02: 이진변수의 합
bin-features=[c for c in train.columns if 'bin' in c]
train['bin_sum']=train[bin_features].sum(axis=1)
test['bin_sum']=test[bin_features].sum(axis=1)
## 파생변수 03 : 단일변수 타겟 비율 분석으로 선정한 변수를 기반으로 Target Encoding을 수행. Target Encoding은 교차검증과정에서 진행
- 파생변수 01 : 운전자 데이터별 결측값의 개수를 더한 값.
- '결측값의 개수' 파생변수는 손쉽게 만들 수 있으며 과거 경진대회에서도 매우 유의미하게 작용
- 결측값의 개수 -> 데이터 내에 새로운 군집정보 제공 가능.
- 갓 운전을 시작하여 막 포르토 세구로 계정을 생성한 경우 숙련된 운전자의 데이터에 비해 더 많은 결측값 존재
- 데이터의 출처에 대한 정보제공
- 포르토 세구로가 운전자에 대한 정보를 전국 지부에서 수집했을 경우, 특정 지점에서 데이터베이스 문제로 특정 열 정보가 사라졌거나 특수한 내부 사정으로 인해 데이터 수집 방법에 오류가 존재해 결측값 처리가 될 수 있다. 이런 데이터 출처에 대한 간접적인 정보 표현 가능
즉,
- 특정 지역에서 수집된 데이터에 같은 변수에서만 결측값이 집중적으로 나타난다면, 해당 지역의 데이터베이스 문제나 수집 절차의 차이를 나타낼 수 있음.
- 초보 운전자(계정 생성 초기 단계)는 데이터를 충분히 입력하지 않았을 가능성이 높아 결측값 개수가 많아질 가능성이 있음.
- 결측값 패턴은 데이터가 얼마나 잘 관리되었는지, 신뢰할 수 있는지에 대한 단서를 제공.
- 파생변수 02 : 이진변수 값의 합
- 변수 간 상호작용으로 얻을 수 있는 고차원 정보 추출. 이진변수는 값이 0 또는 1이기에 각 변수가 파생변수에 미치는 영향력 균등. 실수값 혹 범주형 변수 간의 상호작용 변수를 생성할 경우, 변수별 영향력을 조절하는 작업 필요.
- 승자의 코드에서는 이진변수의 합 뿐만 아니라 모든 이진변수의 값을 문자열로 통합하여 이진변수값의 조합변수 생성 (자세히 어떻게 생성? 더 알아보기)
- 변수 간 상호작용으로 얻을 수 있는 고차원 정보 추출. 이진변수는 값이 0 또는 1이기에 각 변수가 파생변수에 미치는 영향력 균등. 실수값 혹 범주형 변수 간의 상호작용 변수를 생성할 경우, 변수별 영향력을 조절하는 작업 필요.
# 이진 변수 데이터프레임
binary_df = pd.DataFrame({
'binary1': [0, 1, 1, 0],
'binary2': [1, 0, 1, 1],
'binary3': [0, 1, 0, 1]
})
# 이진 변수 값의 합
binary_df['binary_sum'] = binary_df.sum(axis=1)
# 이진 변수 값을 문자열로 통합한 조합 변수 생성
binary_df['binary_combination'] = binary_df.astype(str).agg(''.join, axis=1)
print(binary_df)
즉,
이진변수(0 또는 1)는 간단하지만, 값의 합이 특정 패턴을 나타낼 수 있어.
- 이진변수의 값이 많을수록 특정 이벤트의 발생 가능성을 나타낼 수 있음.
- 모든 이진변수의 값을 문자열로 통합하면, 이진변수 간의 조합을 하나의 파생 변수로 나타낼 수 있어.
- 파생변수 03 : 데이터 탐색 분석 과정에서 선별한 일부 변수를 대상으로 Target Encoding 수행
- Target Encoding : 단일 변수의 고유값별 타겟 변수의 평균값을 파생 변수로 활용하는 피처 엔지니어링 기법(더 자세히 알아보기+예시)
- 1️⃣ Target Encoding이란?
- 특정 변수의 고유값별 **타겟 변수(Target)**의 평균값을 계산하여 새로운 파생변수를 생성하는 기법.
- 변수와 타겟 간의 관계를 반영할 수 있어 모델의 예측 성능 향상에 유용.
- 변수 ps_ind_01이 있고, 타겟 변수 target이 있다면:
- ps_ind_01 == 0인 데이터의 평균 target 값을 계산하여 새로운 변수 ps_ind_01_target_enc에 할당.
- ex) 운전자 A의 'ps_ind_01'변수값이 0일 경우 'ps_ind_01'변수값이 0인 모든 운전자들의 평균 타겟 값을 'ps_ind_01_target_enc' 파생변수로 사용.
from sklearn.model_selection import KFold
# 데이터프레임 생성 (예시)
df = pd.DataFrame({
'ps_ind_01': [0, 1, 0, 1, 0],
'target': [1, 0, 1, 0, 0]
})
# 새로운 변수 생성
df['ps_ind_01_target_enc'] = 0
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_idx, val_idx in kf.split(df):
train_data, val_data = df.iloc[train_idx], df.iloc[val_idx]
# 고유값별 타겟 평균 계산 (훈련 데이터에서만)
mean_target = train_data.groupby('ps_ind_01')['target'].mean()
# 검증 데이터에 매핑
df.loc[val_idx, 'ps_ind_01_target_enc'] = df.loc[val_idx, 'ps_ind_01'].map(mean_target)
print(df)- 타겟 변수의 값을 직접적으로 사용하는 변수 -> 구현을 잘못할 경우 데이터 유출 -> 모델 파이프라인이 망가질 수 O. 데이터 유출 방지를 위해 5-Fold 내부 교차 검증 과정에서 학습에 사용되는 4/5의 훈련 데이터로 변수 고유값별 평균 타겟값 계산 -> 1/5의 검증 데이터에 해당 값을 매핑하는 방식 취함 (더 자세히)
- 5-Fold 교차 검증을 활용한 Target Encoding
1️⃣ 데이터 유출 방지의 원리- 데이터 유출(Data Leakage)이란, 모델이 학습 시 검증 데이터 또는 테스트 데이터의 정보를 미리 학습하는 것을 의미해. 이는 모델 성능을 왜곡시키고, 실전 환경에서 성능 저하를 초래해.
- Target Encoding에서 데이터 유출이 발생하는 경우:
- 전체 데이터에서 특정 변수의 고유값별 타겟 평균을 계산하면, 검증 데이터와 테스트 데이터의 타겟값 정보가 학습 과정에 포함됨.
- 이를 방지하기 위해, 검증 데이터를 제외한 훈련 데이터(4/5)를 활용하여 변수 고유값별 타겟 평균을 계산하고, 이를 검증 데이터(1/5)에만 매핑해야 해.
2️⃣ 5-Fold 내부 교차 검증 방식- 데이터를 **5개의 Fold(부분집합)**로 나눔.
- 각 Fold를 번갈아 가며 검증 데이터로 사용하고, 나머지 4개의 Fold를 훈련 데이터로 사용.
- 훈련 데이터에서 변수 고유값별 타겟 변수의 평균값을 계산.
- 계산된 평균값을 검증 데이터에 매핑.
- 1~4 과정을 모든 Fold에 대해 반복하여, 모든 샘플에 대해 Target Encoding 값을 생성.
- (1) 프로세스
- Target Encoding은 특정 변수의 고유값과 타겟 변수의 평균값을 이용해 새로운 파생변수를 생성하는 기법이지만, 데이터를 잘못 처리하면 데이터 유출 문제가 발생할 수 있어. 데이터를 학습할 때는 모델이 검증 데이터의 타겟값을 미리 알 수 없도록 해야 해. 이를 위해, 5-Fold 내부 교차 검증 방식을 활용하여 Target Encoding을 안전하게 수행할 수 있어.
- 5-Fold 교차 검증을 활용한 Target Encoding
- 5️⃣ 데이터 유출 방지를 위한 5-Fold 교차 검증의 장점
- 타겟값 누출 방지:
- 각 Fold의 검증 데이터는 그 Fold에 포함되지 않은 훈련 데이터로만 타겟 평균값을 계산하여 매핑되므로, 데이터 유출 가능성을 제거함.
- 모든 데이터에 대해 Target Encoding 값 생성 가능:
- 각 Fold의 검증 데이터에 대해 별도의 평균값을 매핑하기 때문에, 최종적으로 모든 데이터가 Target Encoding 값을 가짐.
- 모델의 성능 왜곡 방지:
- 데이터 유출 없이 Target Encoding 값을 생성하므로, 모델의 실전 성능 평가에 왜곡이 발생하지 않음.
- 타겟값 누출 방지:
3. LightGBM 모델 정의
- 학습에 사용할 LightGBM 모델의 설정값 :
- 모델의 복잡도 조절 설정값: num_leaves, max_bin, min_child_samples
- 과적합 방지 설정값 : feature_fraction, subsample, max_drop
- (각 변수에 대한 자세한 설명 추가)
1. 앙상블(Ensemble) - Boosting
머신러닝에서 앙상블 학습이란, 여러개의 다양한 모델의 예측 결과를 결합함으로써 단일 모델보다 신뢰성이 높은 예측값을 얻는 것이다. 캐글이나 데이콘 같은 대회에 참가하다보면 거의 모든 참가자들이 앙상블로 모델을 쌓아 성능을 극대화시키는 모습을 심심치 않게 볼 수 있다. 대표적으로 랜덤 포레스트(random forest)가 있으며, 앙상블 알고리즘을 사용해 단일 결정트리보다 좋은 성능을 내도록 만들어졌다. GBM이 사용하는 Boosting 학습 유형에 대해 설명할것이다.
부스팅 알고리즘은 여러 개의 약한 학습기(weak learner)를 순차적으로 학습-예측하는 방식이다. 이때 잘못 예측한 데이터에 가중치를 부여함으로써 오류를 개선해 나간다. AdaBoost(Adaptive boosting)과 GBM이 이에 속한다. 아래 그림의 상황을 가정해보면, tree 1이 예측하고 남은 잔차들을 tree 2, tree 3를 차례로 지나가면서 줄여가는 것 부스팅 알고리즘이다. 각 tree들을 weak learner라고 보면 된다. 위에서 부스팅 알고리즘은 '가중치 부여를 통해' 오류를 개선해 나간다고 했는데, GBM은 가중치 업데이트에 경사하강법을 이용하는 것이 큰 특징이다. 즉, 손실함수를 최소화하는 방향성을 가지고 가중치 값을 업데이트하는 것이라 할 수 있겠다.

LightGBM은 XGBoost와 함께 부스팅 계열 알고리즘에서 가장 각광받고 있다. LightGBM의 가장 큰 장점은 학습에 걸리는 시간이 적다는 점이다(지금 참고하고 있는 책에서는 GBM->XGBoost->LightGBM 순으로 빠르다고 한다). 그리고 XGBoost와의 예측 성능 차이가 크게 나지도 않는다. 반면 적은 데이터셋에 적용시 과적합이 발생하기 쉽다는 것이 단점이다. 여기서 '적은 데이터셋'이라 함은 통상적으로 10,000건 이하의 데이터셋 정도라고 LightGBM 공식 도큐먼트에서 기술하고 있다.
[ML] GBM 알고리즘 및 LightGBM 소개 - 기본구조, parameters
1. 앙상블(Ensemble) - Boosting 머신러닝에서 앙상블 학습이란, 여러개의 다양한 모델의 예측 결과를 결합함으로써 단일 모델보다 신뢰성이 높은 예측값을 얻는 것이다. 캐글이나 데이콘 같은 대회에
heeya-stupidbutstudying.tistory.com
LightGBM은 XGBoost에 비해 훈련 시간이 짧고 성능도 좋아 부스팅 알고리즘에서 가장 많은 주목을 받고 있다.
GradientBoosting을 발전시킨 것이 XGBoost, 여기서 속도를 더 높인 것이 LightGBM이다. 출처 : https://for-my-wealthy-life.tistory.com/24

LightGBM은 트리 기준 분할이 아닌 리프 기준 분할 방식을 사용한다. 트리의 균형을 맞추지 않고 최대 손실 값을 갖는 리프 노드를 지속적으로 분할하면서 깊고 비대칭적인 트리를 생성한다. 이렇게 하면 트리 기준 분할 방식에 비해 예측 오류 손실을 최소화할 수 있다.
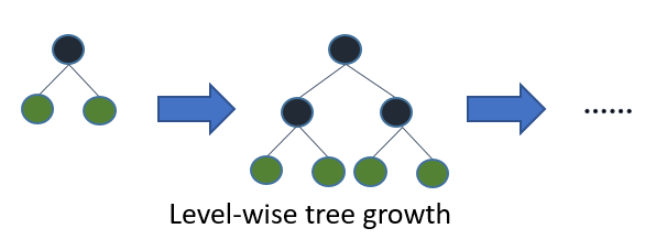
- level-wise 트리 분할: 균형 잡힌 트리 모양을 유지함으로써 트리의 깊이를 효과적으로 줄임 -> overfitting에 강함(대신 트리 균형을 맞추는 데에 시간이 소요됨)
- leaf-wise 트리 분할: 트리의 균형을 맞추지 않고, 최대 손실값(max delta loss)을 가지는 리프 노드 분할 -> 예측 오류 손실을 최소화 할 수 있음(대신 트리의 깊이가 깊어지고 비대칭적임)
4. 모델 학습 및 교차검증 평가
- 교차검증 : 5-Fold StratifiedKFold 기법 사용
5-Fold 교차검증
데이터를 5개의 폴드로 나눈 뒤, 각 폴드가 한 번씩 검증 세트가 되고 나머지 4개 폴드가 훈련 세트가 돼. 즉, 5번의 반복 학습/평가가 이루어지고, 최종 성능은 이 5개의 평가 점수 평균으로 계산해.
- 시계열 데이터 x -> 제공된 데이터를 랜덤하게 분리하여 교차검증에 활용 (과정 자세히)
시계열 데이터 x -> 랜덤하게 분리
- 시계열 데이터가 아닌 경우: 데이터 간의 순서나 시점 관계가 중요하지 않기 때문에 데이터를 랜덤하게 섞어도 모델 성능에 문제가 없어.
- 랜덤 분리의 과정: 데이터를 랜덤하게 분리하면 훈련/검증 세트 간의 데이터가 서로 독립적이 되어 과적합(overfitting)을 방지할 수 있어.
- 분리된 데이터 폴드 내의 타겟변수 비율을 유지하기 위해 사이킷-런의 StratifiedKFold 함수 사용(어떤함순데?
- StratifiedKFold란?
사이킷런(sklearn.model_selection.StratifiedKFold)에서 제공하는 교차검증 기법으로, 폴드마다 타겟 변수(종속변수)의 클래스 비율이 원본 데이터셋과 동일하도록 유지해.
예를 들어, 이진 분류에서 타겟 변수 0과 1의 비율이 70:30이라면, 각 폴드에서도 같은 비율로 데이터를 분리해 줘. - 왜 필요할까?
불균형 데이터(예: 클래스 간 데이터의 수 차이가 큰 경우)에서 특정 클래스가 훈련/검증 세트에 편중되지 않도록 도와. 그렇지 않으면 모델이 특정 클래스에 대해 과대 적합되거나, 성능 평가가 왜곡될 수 있어.
- 재현성을 위해 random_state고정
- random_state란?
데이터 셔플링(랜덤 분리)에서 사용하는 랜덤 시드(seed) 값을 고정하는 설정이야. 고정된 시드 값을 사용하면 항상 동일한 방식으로 데이터를 섞을 수 있어. - 왜 고정해야 할까?
- 결과 재현성 (Reproducibility):
실험 환경을 공유하거나 동일한 설정에서 반복 실험할 때, 결과가 일관되게 나오도록 보장해. - 비교 용이성:
여러 모델을 테스트할 때, 동일한 훈련/검증 데이터셋을 사용함으로써 모델 간 성능을 공정하게 비교할 수 있어. - 데이터 편중 방지:
특정 셔플링 결과가 데이터의 편중된 특성을 드러내지 않도록 항상 같은 방식으로 분리하도록 설정하는 거지.
- 결과 재현성 (Reproducibility):
5. 캐글 업로드
- 위 데이터에서는 피처 엔지니어링을 수행하지 않은 Baseline 모델의 결과물이 미세하게 좋은 점수 기록
- 점수차이가 소수점 이하 4번째 자리수의 미세한 차이 -> 모델 자체가 갖고 있는 랜덤 요소로 인한 편차일 수 있다.
- 피처 엔지니어링이 모델 학습에 전혀 도움을 주지 못했을 수 있다. Target Encoding이 이 경진대회에서는 무의미.
- 3가지 피처 엔지니어링을 동시에 적용했기 때문에 어느 파생변수가 원인인지 확인하기 위해서는 피처 엔지니어링한 변수를 하나씩 추가하여 변인을 하나씩 분석하는 실험을 진행해야 한다.
- Baseline모델에서 사용한 LightGBM 모델이 테이블형 변수를 학습하는 데 특화돼 있으므로 (자세한설명) 이것 활용해보자~
테이블형 데이터는 **범주형 변수(Categorical Features)**와 **연속형 변수(Numerical Features)**로 구성돼 있어. LightGBM은 이 두 종류의 데이터를 모두 효율적으로 처리할 수 있는 알고리즘적 특성을 가지고 있어.
2. Gradient Boosting Decision Tree (GBDT) 기반
- LightGBM은 **Gradient Boosting Decision Tree (GBDT)**를 기반으로 하며, 트리를 통해 데이터의 비선형적 관계를 잘 모델링할 수 있어.
- 트리 모델은 **특성 스케일링(정규화, 표준화)**이 필요 없기 때문에, 테이블형 데이터를 전처리 없이 바로 사용할 수 있어.
- 트리는 특성 간의 상호작용을 자동으로 학습하기 때문에 테이블 데이터의 구조적 관계를 자연스럽게 반영할 수 있어.
3. 범주형 변수의 효율적 처리
- LightGBM은 범주형 데이터를 처리할 수 있는 내장 기능이 있어.
예를 들어, categorical_feature 매개변수를 사용하면 범주형 변수에 대해 원핫 인코딩(One-Hot Encoding)을 하지 않아도 모델이 자동으로 적절히 처리해 줘.
이는 범주형 데이터의 학습 효율성과 메모리 사용량을 개선해.
4. 효율적인 데이터 처리와 학습 속도
- Histogram 기반 학습:
LightGBM은 히스토그램 기반 분할(Histogram-based Splitting) 방식을 사용해 연속형 변수 값을 구간(bin)으로 나누어 계산량을 줄여.
이로 인해 대규모 데이터에서도 빠르게 학습할 수 있어. - Leaf-wise Tree Growth:
LightGBM은 전통적인 트리 학습 방식(Depth-wise) 대신 **리프 중심 성장 방식(Leaf-wise Growth)**을 사용해 불필요한 노드를 줄이고 성능을 높여.- 이 방식은 불균형 데이터와 같은 복잡한 테이블 데이터에서 더 효과적이야.
5. Feature Importance 제공
- LightGBM은 학습된 모델에서 각 변수의 **중요도(Feature Importance)**를 계산해 줘.
이는 테이블형 데이터에서 어떤 변수가 중요한지 확인하는 데 유용해, 데이터 이해와 해석을 돕는 데 특화되어 있어.
6. 파라미터 조정으로 다양한 데이터에 적응 가능
- LightGBM은 하이퍼파라미터를 조정해 테이블형 데이터의 특성에 맞게 최적화할 수 있어.
- max_depth, num_leaves, min_data_in_leaf 등을 조정하여 데이터 크기, 변수 개수, 클래스 불균형 등에 쉽게 적응할 수 있어.
'CS > Data Science' 카테고리의 다른 글
| [Data Science] EPOCH_Kaggle 3주차 (0) | 2025.03.19 |
|---|---|
| [Data Science] EPOCH_Kaggle 2주차 (0) | 2025.03.19 |
| [Data Science] EPOCH_Kaggle 1주차 (1) | 2025.03.06 |
| [Data Science] Kaggle 사용법 (2) | 2025.02.28 |