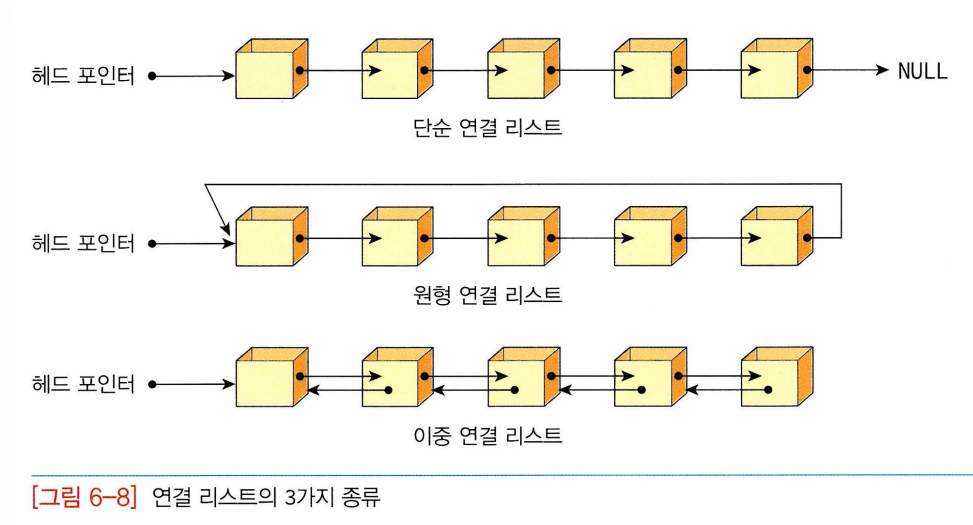
14.1 해싱이란?선형탐색이나 이진탐색은 모두 키를 저장된 키값과 반복적으로 비교함으로써 탐색하고자 하는 항목에 접근-> 최대 가능한 시간 복잡도가 O(로그n)에 그친다. 어떤 응용에서는 더 빠른 탐색 알고리즘 요구해싱은 O(1)의 시간 안에 탐색 끝마칠수도 있다.키에 산술적인 연산 적용 -> 항목이 저장돼있는 테이블의 주소를 계산한여 항목에 접근. 해시테이블: 키에 대한 연산에 의해 직접 접근 가능한 구조해싱: 해시테이블 이용한 탐색14.2 추상자료형 사전사전 : (키,값)쌍의 집합. 키와 관련된 값을 동시에 저장하는 자료구조. (키,값)쌍을 저장할 수도 있고 삭제할수도 있으며 키를 가지고 값을 검색할 수 있다. map이나 table로 불리기도 한다.키 : 사전의 단어처럼 항목과 항목을 구별시켜주는 것..