6.1 리스트 추상 데이터 타입
- 리스트: 순서 또는 위치를 가지는 항목들이 차례대로 저장 (스택과 큐도 리스트의 일종)
- ㄴ집합과는 다름(집합은 항목간 순서가 없기 때문에)
- ㄴ삽입, 삭제, 탐색연산
- 리스트 ADT 구현: 배열(더 간단)과 연결리스트 통해 가능 BUT 크기 고정. 포인터 이용하여 만들수도 있음
- 배열을 사용한 리스트 구현의 장단점
- 장점: 구현 간단, 속도 빠름
- 단점: 리스트 크기 고정, 동적으로 크기 늘리고 줄이기 힘듦, 남은 공간 없으면 더 큰 배열 만들어서 기존 배열 데이터 전부 복사해야 함 > CPU 시간 낭비. 중간에 새로운 데이터 삽입삭제할때도 기존의 데이터 이동해야 함.
- 연결리스트를 사용한 리스트 구현의 장단점
- 장점: 크기 제한 X, 중간에서 쉽게 삽입하거나 삭제 가능한 유연한 리스트
- 단점: 구현 복잡, 임의의 항목을 추출하려 할 때는 배열 사용하는 방법보다 시간 많이 걸림.
6.2 배열로 구현된 리스트 (리스트의 순차적 표현)
-시간 복잡도: 임의의 항목에 접근하는 연산-O(1)(인덱스 사용하여 항목에 바로 접근 가능) , 삽입삭제연산-최악의 경우 O(n)(리스트 거의 다 차 있고 새로운 항목 맨 처음에 삽입할 때.) 최고의 경우: O(1)리스트의 맨 끝에 삽입할 때
6.3 연결리스트
-동적으로 크기가 변할 수 있고 삭제나 삽입 시 데이터를 이동할 필요가 없는 연결된 표현, 포인터 사용하여 데이터 연결, 리스트 구현에만 사용되지 않고 다른 자료구조(트리,그래프,스택,큐) 등 구현에도 많이 사용

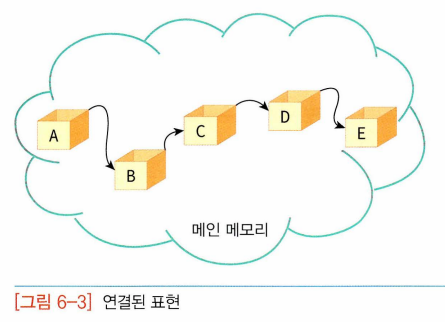
-> 데이터를 한 군데 모아두는 것 포기, 데이터들은 메인메모리상의 어디에나 흩어져서 존재. 이렇게 물리적으로 흩어져 있는 자료들을 서로 연결하여 하나로 묶는 방법: 연결리스트, 상자 연결 줄: 포인터
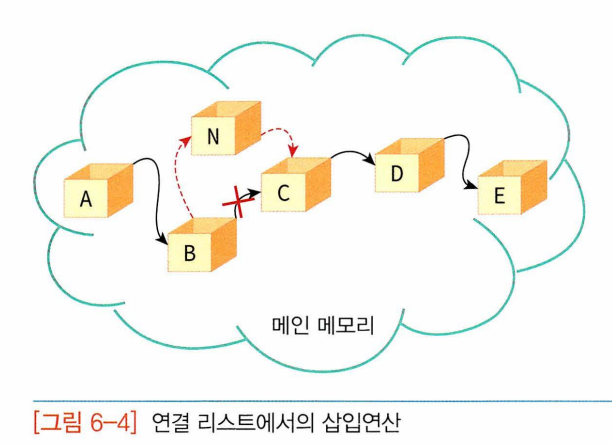

-> 중간에 삽입할 수 O: 줄만 변경해주면 됨
-> 삭제할 때도 데이터 옮길 필요 없이 데이터 연결하는 줄만 수정하면 됨.
- 하나의 프로그램 안에 동시에 여러 개의 연결리스트가 존재할 때 연결리스트 구별은 첫번째 데이터가 함.(줄만 따라가면 나머지 다 얻을 수 있으니까)
-데이터 저장할 공간 필요할 때마다 동적으로 공간 만들어서 쉽게 추가 가능
단점: 배열에 비해 상대적으로 구현 어렵고 오류가 나기 쉬움, 데이터에 더해 포인터까지 저장해야 하므로 메모리 공간 많이 차지함, i번째 데이터 찾으려면 앞에서부터 순차적으로 접근해야 함.
[연결리스트 구조]
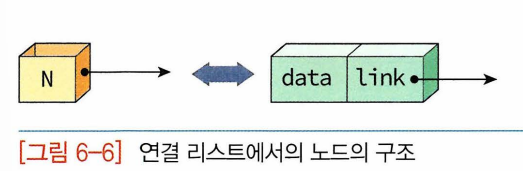
- 상자: node, 연결리스트는 node의 집합
- node는 메모리의 어떤 위치에나 있을 수 있음, 다른 노드로 가기 위해서는 현재 노드가 가진 포인터 이용하면 됨, 노드=데이터필드+링크필드
- 데이터필드: 우리가 저장하고 싶은 데이터(정수~구조체 다양)가 들어감
- 링크필드: 다른 노드를 가리키는 포인터 저장, 이 포인터 이용해서 다음 노드로 건너갈 수 있음
- 연결리스트에서는 연결리스트의 첫번째 노드(헤드) 알아야 전체 노드에 접근할 수 있음 > 연결 리스트마다 첫 번째 노드 가리키고 있는 변수(헤드 포인터) 필요
- 마지막 노드의 링크필드는 NULL로 설정 : 더 이상 연결된 노드가 없음을 의미
- 연결리스트의 노드들은 필요할 때마다 malloc() 이용하여 동적 생성
[연결리스트의 종류]

-> 한 방향으로만 연결(chain), 마지막 노드의 링크가 NULL값 가리킴
-> 단순연결리스트와 같으나 마지막 노드의 링크가 첫 번째 노드 가리킴
-> 각 노드마다 2개의 링크 존재, 한 링크는 앞에 있는 링크 가리키고 또 하나의 링크는 뒤에 있는 링크 가리킴
6.4 단순 연결 리스트

- 핵심연산: 삽입, 삭제
- C언어로 구현 : 노드 정의-자기참조 구조체 / 노드생성-malloc() 호출하여 동적메모리로 생성 / 노드 삭제- free() 호출하여 동적메모리 해제
- 노드 정의: 자기참조구조체(자기 자신을 참조하는 포인터를 포함)

구조체 안에 데이터를 저장하는 data 필드, 포인터 저장돼 있는 link 필드 존재추상 데이터 타입
리스트: 순서 또는 위치를 가지는 항목들이 차례대로 저장 (스태고가 큐도 리스트의 일종 ㄴ집합과는 다름(집합은 항목간 순서가 없기 때문에) ㄴ삽입, 삭제, 탐색연산
리스트 ADT 구현: 배열(더 간단)과 연결리스트 통해 가능 BUT 크기 고정. 포인터 이용하여 만들수도 있음
배열을 사용한 리스트 구현의 장단점
장점: 구현 간단, 속도 빠름
단점: 리스트 크기 고정, 동적으로 크기 늘리고 줄이기 힘듦, 남은 공간 없으면 더 큰 배열 만들어서 기존 배열 데이터 전부 복사해야 함 > CPU 시간 낭비. 중간에 새로운 데이터 삽입삭제할때도 기존의 데이터 이동해야 함.
연결리스트를 사용한 리스트 구현의 장단점
장점: 크기 제한 X, 중간에서 쉽게 삽입하거나 삭제 가능한 유연한 리스트
단점: 구현 복잡, 임의의 항목을 추출하려 할 때는 배열 사용하는 방법보다 시간 많이 걸림.
6.2 배열로 구현된 리스트 (리스트의 순차적 표현)
-시간 복잡도: 임의의 항목에 접근하는 연산-O(1)(인덱스 사용하여 항목에 바로 접근 가능) , 삽입삭제연산-최악의 경우 O(n)(리스트 거의 다 차 있고 새로운 항목 맨 처음에 삽입할 때.) 최고의 경우: O(1)리스트의 맨 끝에 삽입할 때
6.3 연결리스트
-동적으로 크기가 변할 수 있고 삭제나 삽입 시 데이터를 이동할 필요가 없는 연결된 표현, 포인터 사용하여 데이터 연결, 리스트 구현에만 사용되지 않고 다른 자료구조(트리,그래프,스택,큐) 등 구현에도 많이 사용
-> 데이터를 한 군데 모아두는 것 포기, 데이터들은 메인메모리상의 어디에나 흩어져서 존재. 이렇게 물리적으로 흩어져 있는 자료들을 서로 연결하여 하나로 묶는 방법: 연결리스트, 상자 연결 줄: 포인터
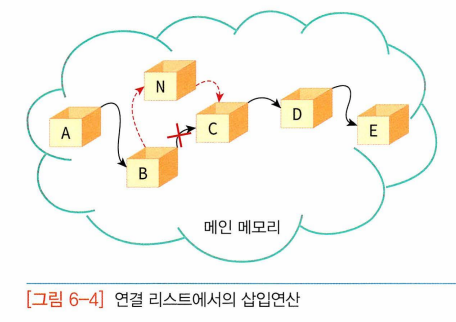
-> 중간에 삽입할 수 O: 줄만 변경해주면 됨
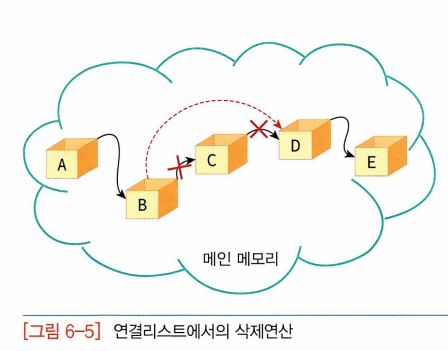
-> 삭제할 때도 데이터 옮길 필요 없이 데이터 연결하는 줄만 수정하면 됨.
- 하나의 프로그램 안에 동시에 여러 개의 연결리스트가 존재할 때 연결리스트 구별은 첫번째 데이터가 함.(줄만 따라가면 나머지 다 얻을 수 있으니까)
-데이터 저장할 공간 필요할 때마다 동적으로 공간 만들어서 쉽게 추가 가능
단점: 배열에 비해 상대적으로 구현 어렵고 오류가 나기 쉬움, 데이터에 더해 포인터까지 저장해야 하므로 메모리 공간 많이 차지함, i번째 데이터 찾으려면 앞에서부터 순차적으로 접근해야 함.
[연결리스트 구조]

-상자: node, 연결리스트는 node의 집합
-node는 메모리의 어떤 위치에나 있을 수 있음, 다른 노드로 가기 위해서는 현재 노드가 가진 포인터 이용하면 됨, 노드=데이터필드+링크필드
데이터필드: 우리가 저장하고 싶은 데이터(정수~구조체 다양)가 들어감
링크필드: 다른 노드를 가리키는 포인터 저장, 이 포인터 이용해서 다음 노드로 건너갈 수 있음
연결리스트에서는 연결리스트의 첫번째 노드(헤드) 알아야 전체 노드에 접근할 수 있음 > 연결 리스트마다 첫 번째 노드 가리키고 있는 변수(헤드 포인터) 필요
마지막 노드의 링크필드는 NULL로 설정 : 더 이상 연결된 노드가 없음을 의미
연결리스트의 노드들은 필요할 때마다 malloc() 이용하여 동적 생성
[연결리스트의 종류]
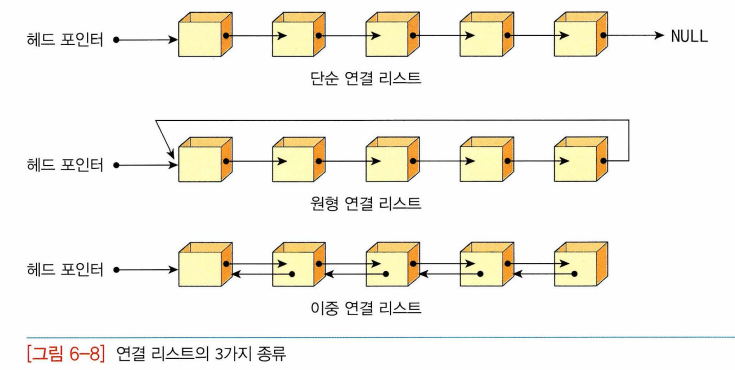
-> 한 방향으로만 연결(chain), 마지막 노드의 링크가 NULL값 가리킴
-> 단순연결리스트와 같으나 마지막 노드의 링크가 첫 번째 노드 가리킴
-> 각 노드마다 2개의 링크 존재, 한 링크는 앞에 있는 링크 가리키고 또 하나의 링크는 뒤에 있는 링크 가리킴
6.4 단순 연결 리스트

핵심연산: 삽입, 삭제
C언어로 구현 : 노드 정의-자기참조 구조체 / 노드생성-malloc() 호출하여 동적메모리로 생성 / 노드 삭제- free() 호출하여 동적메모리 해제
노드 정의: 자기참조구조체(자기 자신을 참조하는 포인터를 포함)

-> 구조체 안에 데이터를 저장하는 data 필드, 포인터 저장돼 있는 link 필드 존재
-> data필드는 element 타입 데이터 저장, link필드는 listNode 가리키는 포인터로 정의
-> ListNode: 노드를 만들기 위한 설계도
-공백리스트의 생성 : 단순 연결리스트는 헤드포인터만 있으면 모든 노드 찾을 수 있음.(어떤 리스트가 공백임을 검사하려면 헤드 포인터가 NULL인지 검사하면 됨.
-malloc() 함수 이용하여 노드 크기만큼의 동적 메모리 할당.


노드 생성
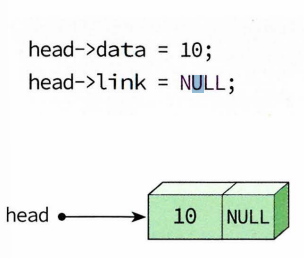

다른 새 노드 생성

노드 연결
6.5 단순 연결 리스트의 연산구현
-리스트 커지면 추상데이터타입에 정의된 전용함수들을 통해 노드 추가하는 것이 편리

- insert_first() : head가 첫번째 노드 가리킴 > 리스트 시작 부분에 노드 추가하는 것 비교적 쉬움 ( 새로운 노드 하나 생성, 새로운 노드 링크에 현재 head값 저장 -> head 변경하여 새로 만든 노드 가리키게하기, insert_first() 는 변경된 헤드포인터 반환
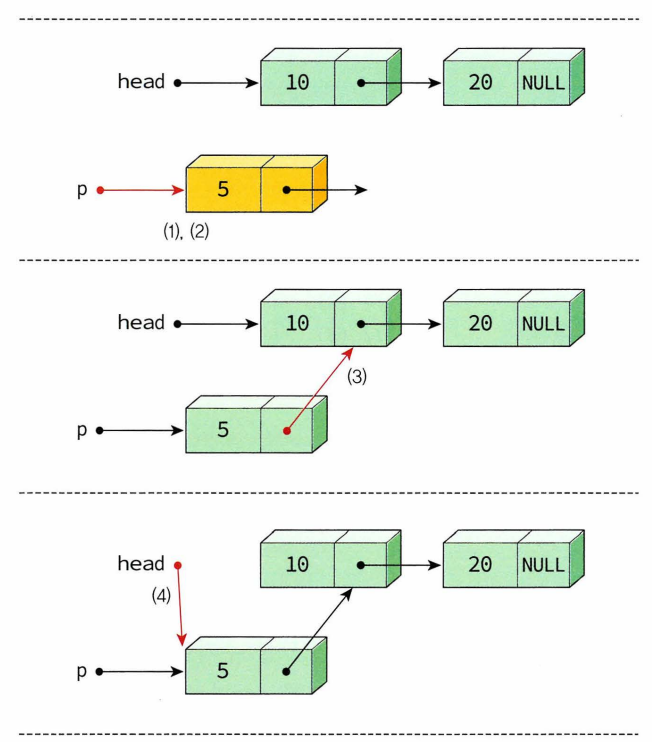
- insert : 삽입되는 위치의 선행노드를 알아야 삽입가능, 새로운 데이터 삽입한 후에 다른 노드들 이동할 필요가 없음.

- delete_first()

- delete()
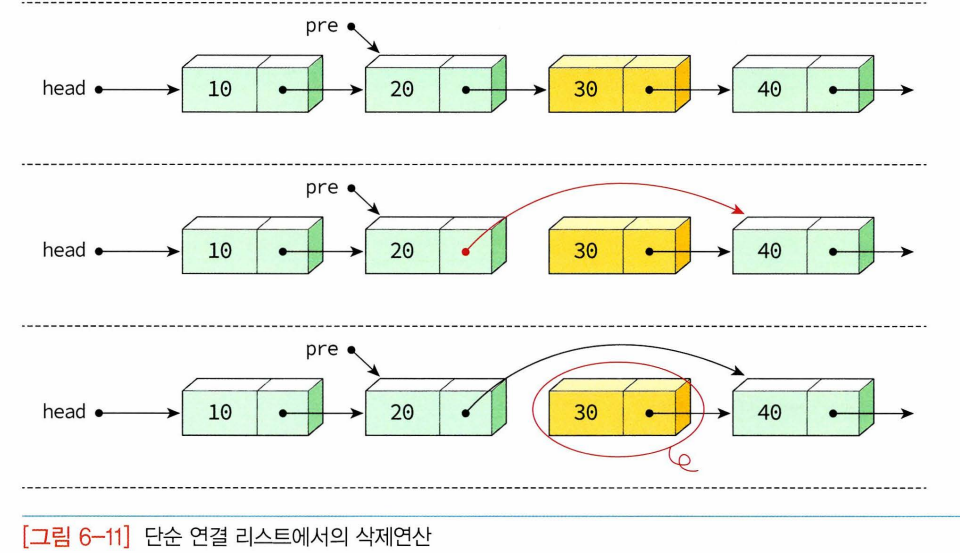
- print_list() : 연결리스트의 노드 방문> 노드 대상으로 다양한 작업 함, 노드 링크값이 NULL이 아니면 계속 링크 따라가면서 노드 방문, NULL이면 연결리스트 끝에 도달한 것이므로 반복 중단(방문연산)
6.6 연결리스트의 응용: 다항식
-연결리스트를 이용하여 다항식 표현! 각 다항식은 다항식의 첫 번째 항 가리키는 포인터로 표현
> 각 항을 하나의 노드로 표현


[덧셈 과정의 3가지 경우]
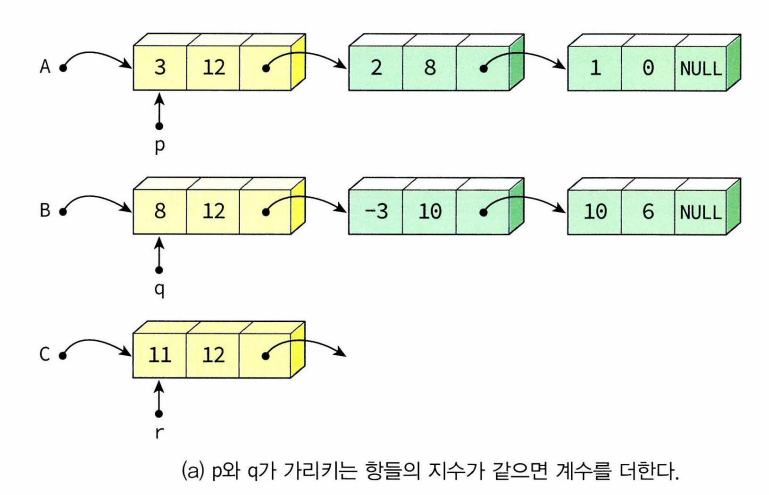
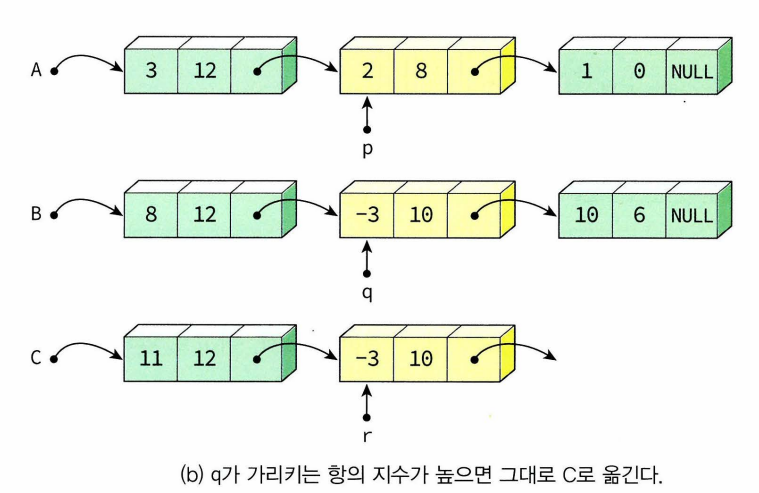


-하나의 연결리스트가 두 개의 포인터 head(첫번째 노드 가리킴)와 tail(마지막 노드 가리킴)로 표현되고 있음. 첫번째와 마지막 노드 동시에 사용하는 경우(헤더노드) 도 많음.(연결리스트에 들어있는 항목들의 개수인 size변수 갖는 경우도 많음)

- 맨 끝에 노드 추가하는 경우 단순연결리스트는 매번 포인터 따라 끝까지 가야 하지만 마지막 노드 항상 가리키는 포인터 있으면 효율적으로 추가 가능.
-항상 연결리스트 생성한 다음 초기화 해줘야 함.
'CS > 자료구조' 카테고리의 다른 글
| [자료구조] chap8. 트리 (0) | 2024.10.22 |
|---|---|
| [자료구조] chap7. 연결리스트 II (0) | 2024.10.21 |
| [자료구조] chap5. 큐 (0) | 2024.10.17 |
| [자료구조] chap4. 스택 (4) | 2024.10.16 |
| [자료구조] chap3. 배열, 구조체, 포인터 (1) | 2024.10.12 |