이화여자대학교 캡스톤졸업프로젝트로 진행한 handDoc 서비스에서 제가 담당한 수어 인식(Sign-to-Text) AI 모델 구축 과정 전체를 튜토리얼로 정리해보았습니다. 누구나 쉽게 따라할 수 있도록 쉽게 풀어 정리해봤어요~~
데이터 처리 → 전처리 → 증강 → 모델 학습 → 평가까지 전 단계를 상세히 설명하였으니, 이 글만 따라오면 당신도 수어인식모델을 쉽게 학습시킬 수 있답니다~!!
(편의상 ~다 체로 진행하겠습니다.)
1. 프로젝트에서 수어 인식 모델이 필요한 이유
우선 우리 프로젝트를 간단히 설명해보고자 한다. (자세한 기획내용은 'handDoc 기획' 글을 참고해주세요! ^^)
handDoc은 청각장애인 환자의 비대면/대면 진료를 지원하는 서비스이며, 그 핵심 기능 중 하나가 사용자의 수어를 실시간 텍스트로 변환하는 기능이다. 이 AI 모델을 위한 데이터전처리 및 학습을 나와 타 팀원이 함께 담당하였고 실험 및 비교를 통해 내가 학습시킨 Bi-LSTM을 실사용하게 되었다.
2. 전체 파이프라인 요약
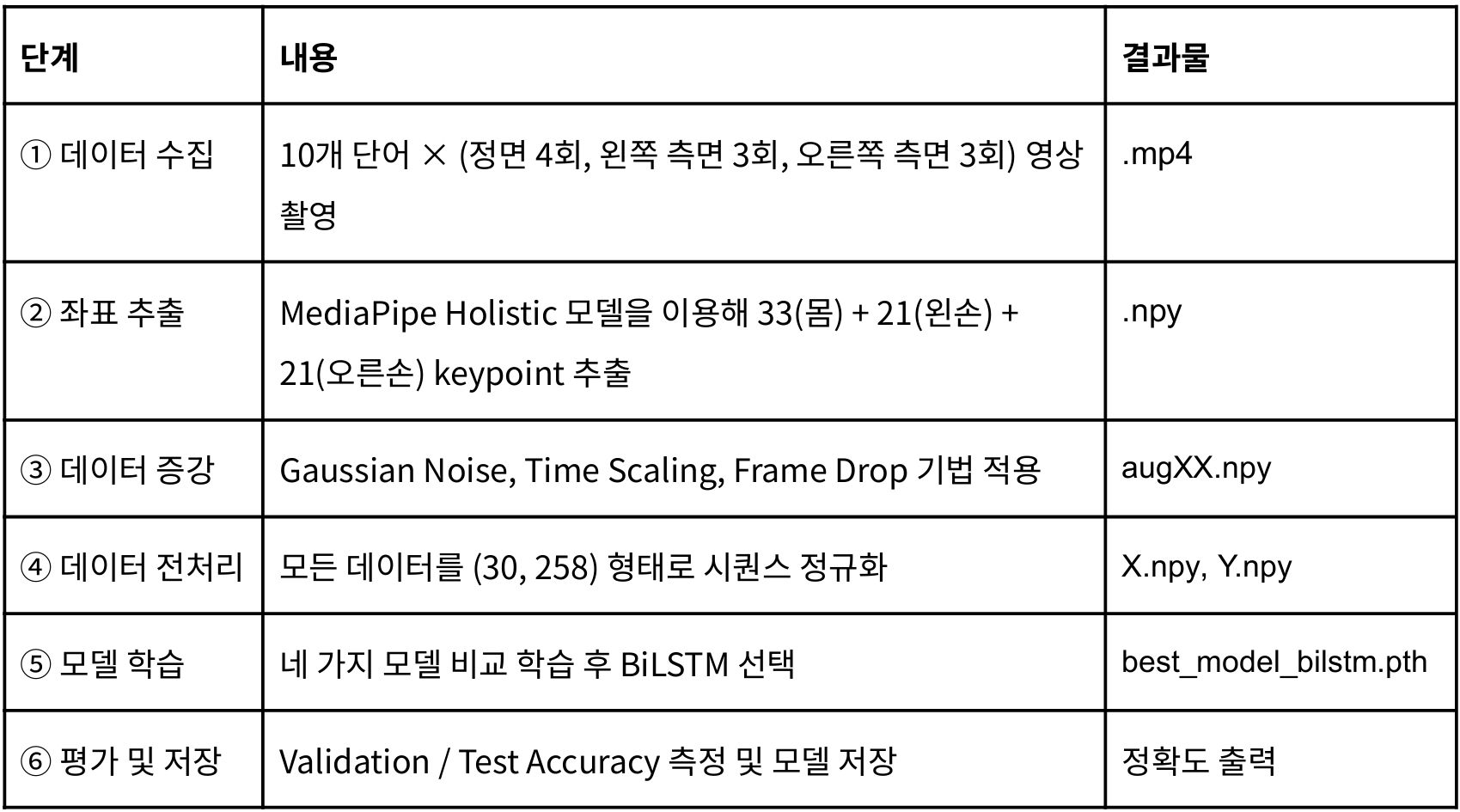
이 튜토리얼은 위 과정을 하나씩 순서대로 따라하는 방식으로 구성된다.
일단 우리는 데이터를 직접 촬영!하였다. 10개 단어를 각각 표와 같이 다양한 각도에서, 1인당 10개씩 팀원 3명이서 영상을 촬영하여 총 10*3*10 = 300개의 영상을 촬영하였다는..ㅎ
이 영상들에서 MediaPipe Holistic 모델을 통해 키포인트를 추출하고, 데이터증강 - 전처리 - 모델학습 - 모델선정 - 평가 및 저장 을 진행했다.
3. 데이터 처리 튜토리얼
3-1. MediaPipe Holistic으로 keypoint 추출하기
설치
mediapipe는 다음 명령어를 통해 쉽게 설치할 수 있다.
pip install mediapipe opencv-python numpy핵심 코드
좌표 추출 핵심 코드는 다음과 같다.
import mediapipe as mp
import cv2
import numpy as np
mp_holistic = mp.solutions.holistic
def extract_keypoints(frame):
with mp_holistic.Holistic() as model:
results = model.process(frame)
pose = []
lh = []
rh = []
if results.pose_landmarks:
for lm in results.pose_landmarks.landmark:
pose.extend([lm.x, lm.y, lm.z, lm.visibility])
if results.left_hand_landmarks:
for lm in results.left_hand_landmarks.landmark:
lh.extend([lm.x, lm.y, lm.z])
if results.right_hand_landmarks:
for lm in results.right_hand_landmarks.landmark:
rh.extend([lm.x, lm.y, lm.z])
return np.array(pose + lh + rh)출력 형태
- Pose: 33 × 4
- Left hand: 21 × 3
- Right hand: 21 × 3

→ 총 258차원이다.
한 프레임은 총 258차원이며, 30fps 기준 1초 영상은 (30, 258) 형태의 NumPy 배열로 저장된다.
3-2. 프레임 정규화 (30프레임 고정)
영상마다 프레임 길이가 달라 선형 보간(Linear Interpolation)으로 모든 영상을 30프레임으로 고정했다.

3-3. 데이터 증강 세 가지
실 사용 환경의 변화를 반영하기 위해 3가지 augmentation을 적용했다.

→ 원본 1개당 49개의 증강 샘플 생성 → 총 15,000개 학습 데이터 확보(10단어 기준)
각 증강의 자세한 코드는 다음과 같다. 참고하여 코딩해보길 바란다.
(1) Gaussian Noise
def add_noise(arr):
noise = np.random.normal(0, 0.01, arr.shape)
return arr + noise(2) Time Scaling
def time_scale(arr, scale):
idx = np.linspace(0, len(arr)-1, int(len(arr)*scale))
idx = np.clip(idx, 0, len(arr)-1)
return arr[idx.astype(int)](3) Frame Drop
def frame_drop(arr, drop_ratio=0.1):
drop_n = int(len(arr) * drop_ratio)
keep_idx = sorted(np.random.choice(len(arr), len(arr)-drop_n, replace=False))
return interpolate_frames(arr[keep_idx])
3-4. 라벨 구성 & 데이터셋 저장
폴더명을 기준으로 자동 라벨링 했고, classes.npy / Y.npy로 저장했다. 또한 Stratified Split으로 train/val/test의 클래스 비율을 동일하게 유지했다.

저장 구조:
classes.npy # 단어 라벨
X.npy # (N, 30, 258)
Y.npy # 정수 라벨
file_names.npy # 데이터 누수 방지용4. 모델 학습 튜토리얼
4-1. 테스트한 모델
위와 같은 전처리한 데이터셋을 아래 모델에 각각 넣어보았다. 학습설정은
- Optimizer: Adam(lr=0.001, weight_decay=1e-4)
>> 안정적이고 빠른 학습 + 과적합 억제 - Loss: CrossEntropyLoss
>> 다중 클래스 분류 표준 손실 함수 - Scheduler: CosineAnnealingLR(T_max=10)
>> 학습률을 점진적으로 감소시켜 안정적 수렴 - Epoch: 30
>> 데이터 규모 기준 과적합 직전까지 충분히 학습되는 범위 - Batch Size: 32
>> 메모리 효율·일반화 성능 균형점
로 진행했다.
각 모델의 특징은 다음과 같다.

4가지 모델 중, 양방향 시퀀스를 모두 활용하여 현재시점 데이터를 해석하는 모델인 Bi-LSTM이 시계열적 데이터인 수어를 효과적으로 학습해, 가장 높은 정확도인 98.9%를 보였다.

4-2. BiLSTM 모델 정의
아래와 같은 코드로 Bi-LSTM을 구성했다.

코드 설명을 간단히 하자면,
1) __init__ — 모델 구조 정의
self.lstm = nn.LSTM(
input_size=258, # 프레임당 특징 258차원
hidden_size=256, # 은닉 상태 크기
num_layers=3, # LSTM 레이어 3층
batch_first=True, # 입력 형태가 (B, T, F)
bidirectional=True, # 양방향 LSTM
dropout=0.5
)
- 258차원 keypoint를 입력받고 3층 Bi-LSTM으로 시계열 특징을 학습한다.
- Bidirectional=True → forward + backward 둘 다 사용해서 문맥을 더 잘 잡아낸다.
- 출력 크기: 256×2 = 512
self.bn = nn.BatchNorm1d(hidden_size * 2)
self.dropout = nn.Dropout(0.5)
self.fc = nn.Linear(hidden_size * 2, num_classes)
- BatchNorm으로 안정화, Dropout으로 과적합 방지, 마지막 Linear로 클래스 수(10개)를 예측한다.
2) forward — 입력을 모델에 통과시키는 과정
out, _ = self.lstm(x) # out: (B, 30, 512)
- 30프레임 전체를 LSTM에 넣으면 각 프레임마다 은닉상태(512차원)가 생성된다.
out = out[:, -1, :] # 마지막 프레임의 은닉상태만 가져옴
- 문장을 요약할 때 마지막 은닉 상태를 쓰는 것처럼, 수어 시퀀스의 마지막 타임스텝 표현만 사용한다.
out = self.bn(out)
out = self.dropout(out)
return self.fc(out) # (B, num_classes)
- 정규화 + dropout 적용
- 마지막 linear로 클래스 예측
즉, (30, 258) 시퀀스를 3층 양방향 LSTM으로 인코딩하고, 마지막 프레임의 은닉 벡터(512차원)를 기반으로 11개 단어 중 하나를 분류하는 구조이다.

4-3. 평가 결과

검증 정확도 최고 시점의 모델(best_model)을 저장했고, best_model_bilstm.pth로 테스트셋을 평가했다.
4-4. 최종 모델 저장 구조
best_model_bilstm.pth
classes.npy
X.npy / Y.npy
file_names.npy5. handDoc 서비스 적용 결과
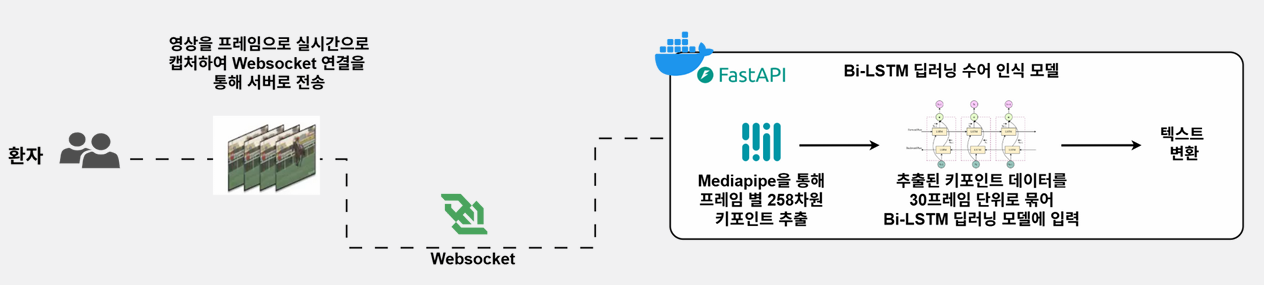
위 아키텍처는 handDoc에서 환자의 영상 → 텍스트로 변환되는 전체 흐름을 나타낸다.
- 환자 단말에서 영상 프레임 실시간 캡처
웹캠으로 촬영된 영상이 1프레임 단위로 잘려 전송된다. - WebSocket을 통해 FastAPI 서버로 전송
HTTP 요청보다 빠른 양방향 연결을 사용해 지연 시간을 최소화한다. - FastAPI 서버에서 MediaPipe로 키포인트 추출
각 프레임마다- Pose 33개
- 양손 keypoint 21 + 21개
총 258차원 벡터로 변환된다.
- 30프레임 단위로 묶어 Bi-LSTM 모델 입력
추출된 벡터 시퀀스를 (30, 258) 형태로 정규화한 뒤
딥러닝 기반 Bi-LSTM 수어 인식 모델에 넣어 단어를 예측한다. - 예측된 단어를 텍스트로 변환해 의사 화면에 출력
모델이 감지한 단어는 바로 텍스트로 변환되어 실시간으로 의사에게 전달된다.
모델은 위와 같은 구조로 실시간 인식 파이프라인을 구성하며, 서비스 적용 결과는 다음과 같다.
- 실시간 수어를 텍스트로 안정적으로 변환
- 키포인트 기반 방식이라 배경,조명,해상도 영향이 거의 X
- 학습된 Bi-LSTM 모델 기준 테스트 정확도 98.9%
- 실제 사용자 테스트에서도 지연 없이 자연스럽게 동작
6. 결론 및 확장 계획
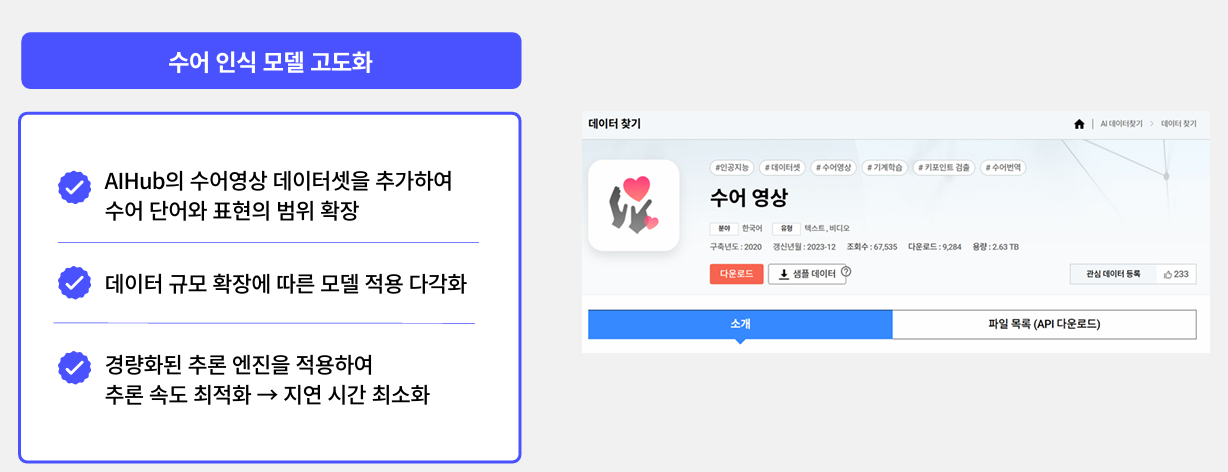
이후 서비스 고도화를 위해, AIHub의 수어영상 데이터셋을 추가하여 수어 단어, 표현 범위를 확장하고자 한다. 또 ONNX로 경량화된 추론엔진을 적용하여 추론속도를 최적화하고 지연시간을 최소화하는 것이 우리 노페인노게인 팀의 목표이다.
다들 이 블로그를 참고하여, 수어 인식 모델 학습에 도전해보길 바랍니다. 읽어주셔서 감사합니다:)
'프로젝트 > EWHA 캡스톤 졸업프로젝트' 카테고리의 다른 글
| [handDoc] 25-2 Ewha Capstone Design 졸업프로젝트 대상 (0) | 2026.02.25 |
|---|---|
| [handDoc] 배포 환경 구축 정리 (AWS EC2 + Docker + Nginx + FastAPI + Spring Boot) + 트러블슈팅 (0) | 2025.11.23 |
| [handDoc] BE ERD 및 API 설계 (0) | 2025.11.23 |
| [handDoc] AI 모델(수어인식/음성교정) 구축 과정 (1) | 2025.11.18 |
| [handDoc] 서비스 핵심 기능과 전체 아키텍처 설계 (0) | 2025.11.18 |