handDoc 프로젝트에서는 수어인식모델, 음성교정모델 2가지 종류의 AI를 사용했다.
수어인식모델인 Bi-LSTM은 데이터셋을 직접 구축하여 딥러닝 학습시켰으며, 청각장애인의 부정확한 음성을 인식하여 교정하는 모델인 Whisper은 파인튜닝 방법을 사용하였다.
1. 딥러닝 기반 수어인식모델
(1) 개요
handDoc 서비스에서는 수어를 사용하는 청각장애인 환자가 자신의 수어를 실시간 텍스트로 변환해 의사에게 전달할 수 있도록 수어 인식 모델을 구축했다. Google MediaPipe Holistic으로 상반신 keypoint를 추출하고, 이를 기반으로 1D-CNN / LSTM / CNN+LSTM / BiLSTM 네 가지 모델을 각각 학습했다. 그중 Validation Accuracy 98.9%를 기록한 BiLSTM을 최종 모델로 선정했다.
전체 파이프라인은 다음과 같다.
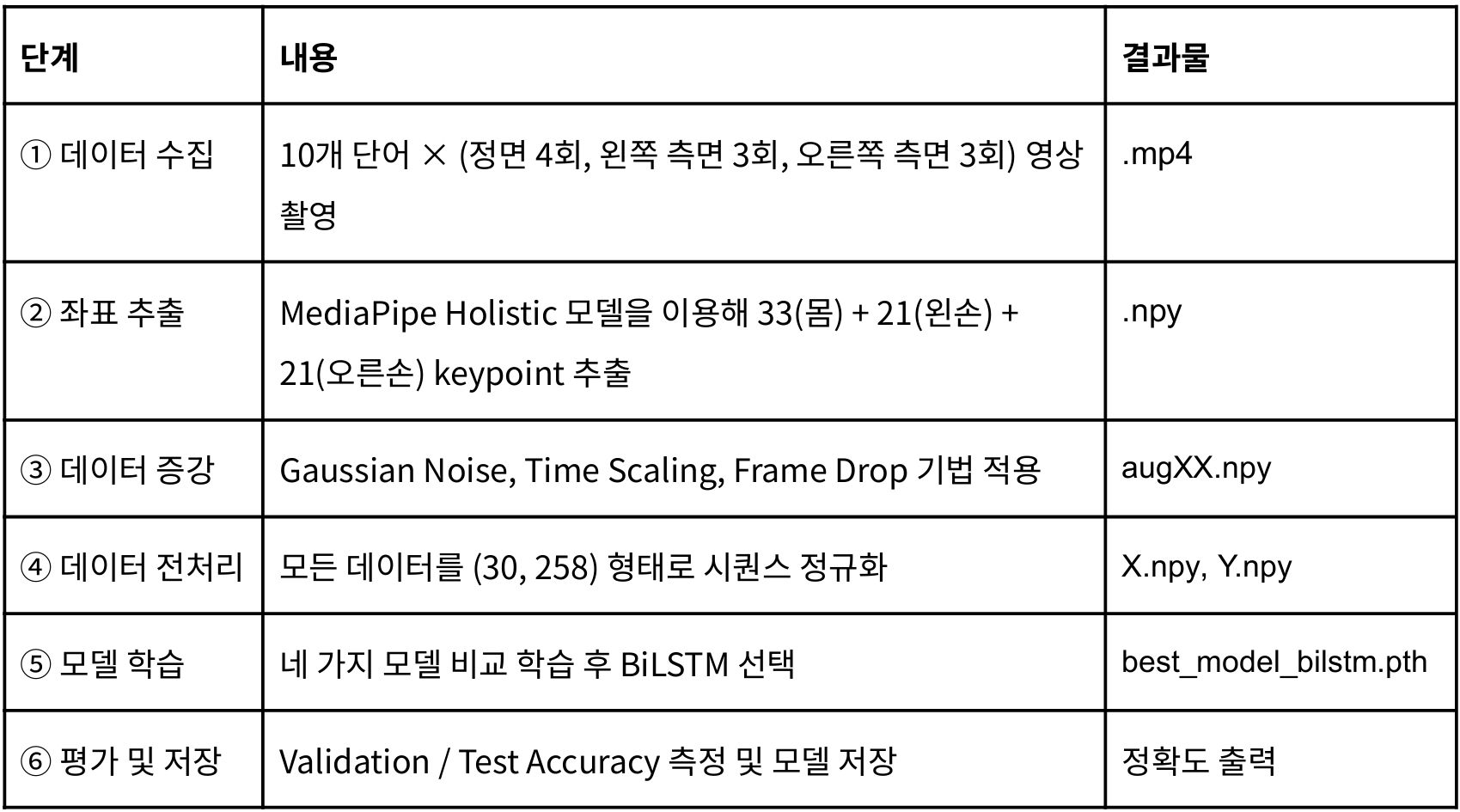
(2) 데이터 처리 단계
2-1. MediaPipe 기반 좌표 추출
MediaPipe Holistic으로 다음 세 부위 keypoint를 추출했다.
| 부위 | 개수 | 좌표 차원 |
| Pose | 33 | (x,y,z,visibility) |
| Left Hand | 21 | (x,y,z) |
| Right Hand | 21 | (x,y,z) |
한 프레임은 총 258차원이며, 30fps 기준 1초 영상은 (30, 258) 형태의 NumPy 배열로 저장된다.
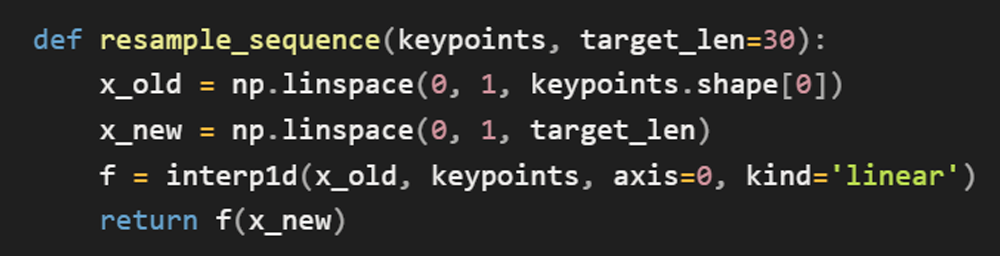
2-2. 프레임 정규화
영상마다 프레임 길이가 달라 선형 보간(Linear Interpolation)으로 모든 영상을 30프레임으로 고정했다.
2-3. 데이터 증강
실 사용 환경의 변화를 반영하기 위해 3가지 augmentation을 적용했다.
| 기법 | 설명 | 목적 |
| Gaussian Noise | 모든 좌표에 N(0, 0.01²) | 손 떨림/흔들림 |
| Time Scaling | 속도 0.8~1.2배 변형 | 동작 속도 다양화 |
| Frame Drop | 특정 프레임 제거 후 보간 | 프레임 누락 대응 |
→ 원본 1개당 49개의 증강 샘플 생성 → 총 15,000개 학습 데이터 확보(10단어 기준)
2-4. 데이터셋 구성
폴더명을 기준으로 자동 라벨링 했고, classes.npy / Y.npy로 저장했다.
Stratified Split으로 train/val/test의 클래스 비율을 동일하게 유지했다.

(3) 모델 설계 및 테스트
3-1. 테스트한 모델
각 모델의 특징은 다음과 같다.
| 모델 | Test Acc | 특징 |
| 1D-CNN | 91.67% | 프레임 단위 특징 추출, 시계열 정보 약함 |
| LSTM | 87.50% | 시간 순서 반영, 단방향 |
| CNN+LSTM | 70.00% | 공간·시간 정보 모두 사용, 일반화 낮음 |
| BiLSTM | 98.90% | 양방향 문맥 학습, 최고 정확도 |

3-2. 최종 모델 구조 (BiLSTM)


3-3. 학습 설정
- Optimizer: Adam(lr=0.001, weight_decay=1e-4)
안정적이고 빠른 학습 + 과적합 억제 - Loss: CrossEntropyLoss
다중 클래스 분류 표준 손실 함수 - Scheduler: CosineAnnealingLR(T_max=10)
학습률을 점진적으로 감소시켜 안정적 수렴 - Epoch: 30
데이터 규모 기준 과적합 직전까지 충분히 학습되는 범위 - Batch Size: 32
메모리 효율·일반화 성능 균형점
3-4. 학습 및 평가

검증 정확도 최고 시점의 모델을 저장했고, best_model_bilstm.pth로 테스트셋을 평가했다.
3-5. 저장 구조
- best_model_bilstm.pth : 최적 성능 모델 가중치
- classes.npy : 단어 라벨 리스트
- X.npy / Y.npy : 학습용 데이터셋
- file_names.npy : 데이터 누수 방지용 파일명 목록
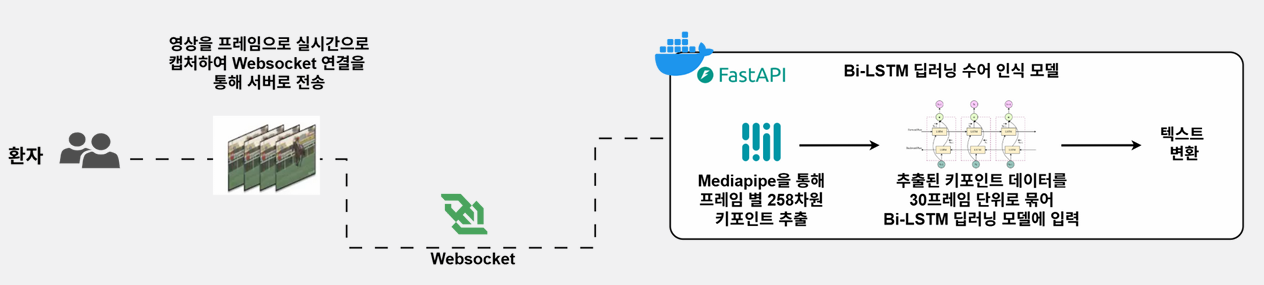
(4) 결론 및 계획

2.5.2 파인튜닝 Whisper 모델
(1) 개요
기존에는 다음과 같은 방식으로 GPT 추천문장을 만들었다.
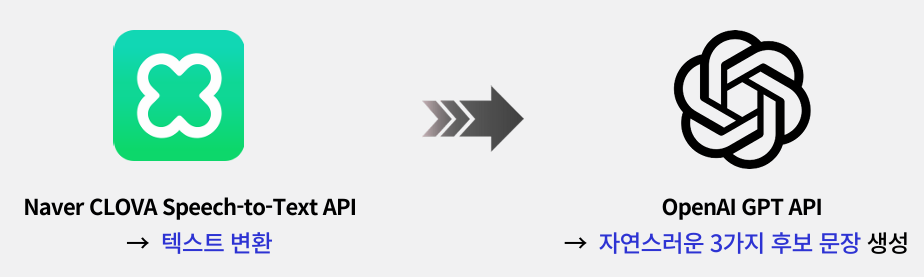
그러나 위처럼 네이버 클로바로만 STT를 진행하면 청각장애인의 부정확한 발음을 제대로 인식하지 못하는 이슈가 생길 수 있다고 생각했다. 따라서 수어 대신 구음을 활용하는 청각장애인을 위해 Whisper를 ʻ구음장애 음성’ 도메인에 특화되도록 파인튜닝했다. 기존 Whisper는 발화 특성을 거의 인식하지 못하므로 도메인 맞춤 모델이 필요했다.
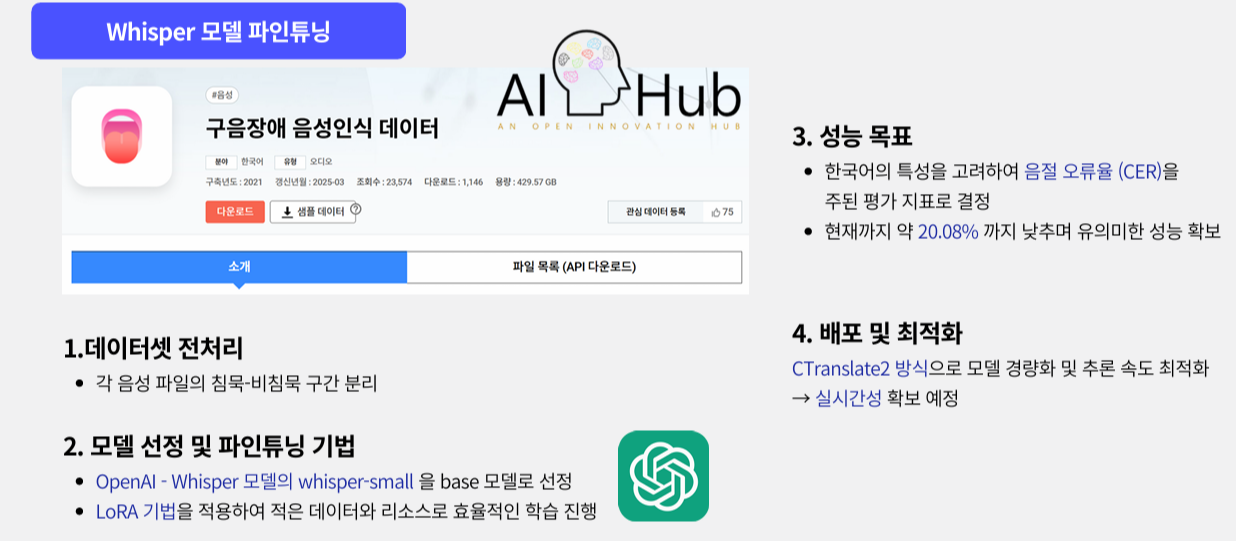
(2) 데이터 처리
2.1 데이터셋 확보
AI-Hub의 구음장애 음성인식 데이터를 사용했다. (.wav + .json)
2.2 전처리
- 음성 분할
침묵·비침묵 구간 분리 후 발화 구간만 개별 .wav로 저장 - 텍스트 정규화
문장 부호 기준 분리, 불필요 문자 제거 - 병합 및 검증
음성 세그먼트와 텍스트를 1:1 매칭한 뒤 개수 검증
(3) 모델 설계 및 테스트
3.1 베이스라인
Whisper-small을 그대로 실행해 성능을 측정했다.
- WER 98.97%
- CER 93.62%
→ 원본 모델이 구음장애 음성을 거의 처리하지 못함을 확인
3.2 파인튜닝 전략
GPU 메모리 효율을 위해 PEFT 기반 LoRA 적용.
핵심 원리:
- load_in_8bit=True로 원본 가중치를 8bit 양자화
- q_proj, v_proj 등 핵심 레이어에 LoRA 어댑터만 부착해 소수 파라미터만 학습
3.3 하이퍼파라미터 실험
- r=8 (lora_alpha=32)
- r=16 (lora_alpha=64)
두 설정만 변경하고 동일 조건에서 10 epoch 학습했다.
3.4 결과
| 모델 | Best WER | Best CER |
| Baseline | 98.97 | 93.62 |
| r=8 | 43.81 | 20.08 |
| r=16 | 44.85 | 20.61 |
r=8이 두 지표에서 모두 우수해 최종 선정했다.
(4) 결론
파인튜닝 전 Whisper-small은 구음장애 음성을 거의 인식하지 못했다.
그러나 LoRA 기반 파인튜닝을 적용한 후 WER과 CER이 큰 폭으로 개선되어 구음장애 음성을 일정 수준 이상 인식할 수 있는 작동 가능한 모델로 발전했다는 점에 의의가 있다.
다만 실시간 자막에 직접 적용하기에는 정확도가 충분하지 않아, Whisper 결과를 GPT-4o에 전달해 문맥을 기반으로 한 3가지 후보 문장을 생성하도록 구현했다. 이를 통해 1차 STT 모델의 한계를 2차 LLM의 문맥 이해 능력으로 보완함으로써, 사용자에게 보다 정확한 텍스트 변환 결과를 제공할 수 있게 되었다.
'프로젝트 > EWHA 캡스톤 졸업프로젝트' 카테고리의 다른 글
| [handDoc] 수어 인식 모델 구축 튜토리얼 : MediaPipe → BiLSTM 학습까지 전 과정 (0) | 2025.11.24 |
|---|---|
| [handDoc] 배포 환경 구축 정리 (AWS EC2 + Docker + Nginx + FastAPI + Spring Boot) + 트러블슈팅 (0) | 2025.11.23 |
| [handDoc] BE ERD 및 API 설계 (0) | 2025.11.23 |
| [handDoc] 서비스 핵심 기능과 전체 아키텍처 설계 (0) | 2025.11.18 |
| [handDoc] 청각장애인 대상 진료 플랫폼, handDoc 기획 (1) | 2025.11.12 |