* 챕터목표 : data plane을 중심으로 network layer service의 원리 이해
4.1 네트워크 계층 개요
- network layer service models (transport 계층의 서비스 모델은 p2p, client-server가 있었다.)
- forwarding 대 routing (네트워크 계층의 핵심기능-transport 계층의 mux, demux처럼-여러개의 기능: flow control, congestion control, reliable data transfer... *transport 계층은 end system에만 올라가는 protocal 계층. network 계층부터는 network core의 router에도 탑재가 되게 되는 프로토콜 )
- 라우터(network core에 있는 장비, network 계층)의 작동 방식
- 일반화된 forwarding- 지금까지는 packet header 목적지 주소 보고 forward. 하지만 packet header중 여러개를 경우에 따라 볼 수 o. (ex. link 계층 header도 일부러 볼 수 있게 해줌)
- 네트워크 계층
- Data plane : forwarding 맡음
- Control plane : routing 맡음

- 네트워크 계층 서비스 및 프로토콜
- 송신 호스트에서 수신호스트까지의 전송 segment. NW계층은 호스트 간 통신서비스 구현, 가장 복잡한 계층.
- 모든 인터넷 장치의 네트워크 계층 프로토콜 : host, router
- sender : network 계층에서 transport 계층의 segment를 받아서 이를 network 계층 에서 IP계층 datagram으로 encapsulate(IP계층에 필요한 control을 위한 header 붙이기)해서 protocal stack 타고 내려와서 first of router로 가 link layer를 지난다.
- receiver : segment를 transport layer protocol로 전달 (sending host가 보낸, link 계층이 올려주는 datagram 받아서 IP header 떼어내어 decapsulate 하고 sender측 transport가 만들었던 segment를 transport 계층에 올려줌 + segment를 받아서 encapsulate해서 link 계층으로 넘겨주는 network 계층(sending host와 receiving host에 들어있음) 이 있지만 매우 단순한 역할
- sending, receiving host는 router뿐만 아니라 여러 곳에 분포 / network 계층 프로토콜은 sending , receiving host뿐 아니라 network core에 있는 router들에도 존재. application과 transprot 계층 프로토콜은 sending host와 receiving host에만 존재.
- routers : router를 통과하는 모든 IP datagram(packet 들어오면 header field 검사해서 다음 hope으로 정보에 따라 forward 해주는 역할) 의 header fields를 검사.
- forwards datagram : 데이터그램을 입력포트에서 출력포트로 이동 -> end-end 경로 따라서 datagram 전송

- 네트워크 계층의 두 가지 key functions
- forwarding : 라우터의 입력링크에서 적절한 라우터 출력 링크로 패킷이동 (packet이 router의 input link로 들어오면 적절한 output link로 뽑아준다.(link 여러개 중 packet이 들어온 link : intputlink, packet이 다음 hope으로 나가는 link : output link
- single 고속도로 분기점 통과과정 (intersection 만날 때마다 어디로 갈지 결정 -> Data plane)
- routing : 패킷이 source에서 목적지까지 이동하는 경로 결정
- routing protocal : protocol에 따라 router끼리 router에 대한 정보 주고받기-> route 결정
- routing algorithm : 경로 계산
- source에서 목적지까지 route planning -> control plane)
- forwarding : 라우터의 입력링크에서 적절한 라우터 출력 링크로 패킷이동 (packet이 router의 input link로 들어오면 적절한 output link로 뽑아준다.(link 여러개 중 packet이 들어온 link : intputlink, packet이 다음 hope으로 나가는 link : output link
- network layer
- Data plane (forwarding)
- local, router별 기능 - 각 router들이 알아서 하고 router이 local하게 혼자 결정한 정보 -> 딴 애한테 어떻게 할지 묻지 x.
- 라우터 입력 포트에 도착한 데이터그램이 라우터 출력포트로 전달되는 방식 결정 : intput으로 들어온(어떠어떠한 목적지 갖고 온) 애 어느 output port로 뽑을지 결정
- forwarding 기능
- destination based forwarding : 목적지만 보고 결정
- generalized forwarding : 하나 이상의 port 보고 결정, forward 이외 drop, 검사 등 다양한 action 취할 수 o
- Control plane (routing)
- 네트워크 wide 로직 : 전체 network 상황에 따라 route 결정 (source-destination 이르는 길 결정 : traditional routing 이라 할지라도 network wide로 결정)
- source 호스트에서 목적지 호스트까지 종단경로를 따라 라우터 간 datagram이 routed(end to end path : route 계산 : network ideal logic) 되는 방식 결정.
- 2가지 control-plane 접근방식
- traditional routing 알고리즘 : router에서 구현 - destination based forwarding과 연관(per router)
- software-defined 네트워킹(SDN) : (원격) 서버에서 구현 - > generalized forwarding 과 연관 (logically centralized-centralized server가 혼자 계산)
- Data plane (forwarding)

- per-router control plane(router가 혼자 하는 것은 x)
- 모든 router의 개별 routing 알고리즘 구성 요소는 contrrol plane에서 상호작용
- 대부분의 인터넷에서 사용되는 routing
- destination based forwarding
- same device에서 router에서 두 가지 역할 : control plane과 data plane 기능(control plane에서 forwarding table을 작성(혼자 결정 x)해서 data plane으로 내려보내면 local한 per router function에서 forwarding table만 보고 packet forwarding 결정(destination based forwarding)
- consistent한 map 그림 : map이 일치하지 않으면 map이 엉킴. network round logic이기 때문에 routing decision은 같은 경로 생각
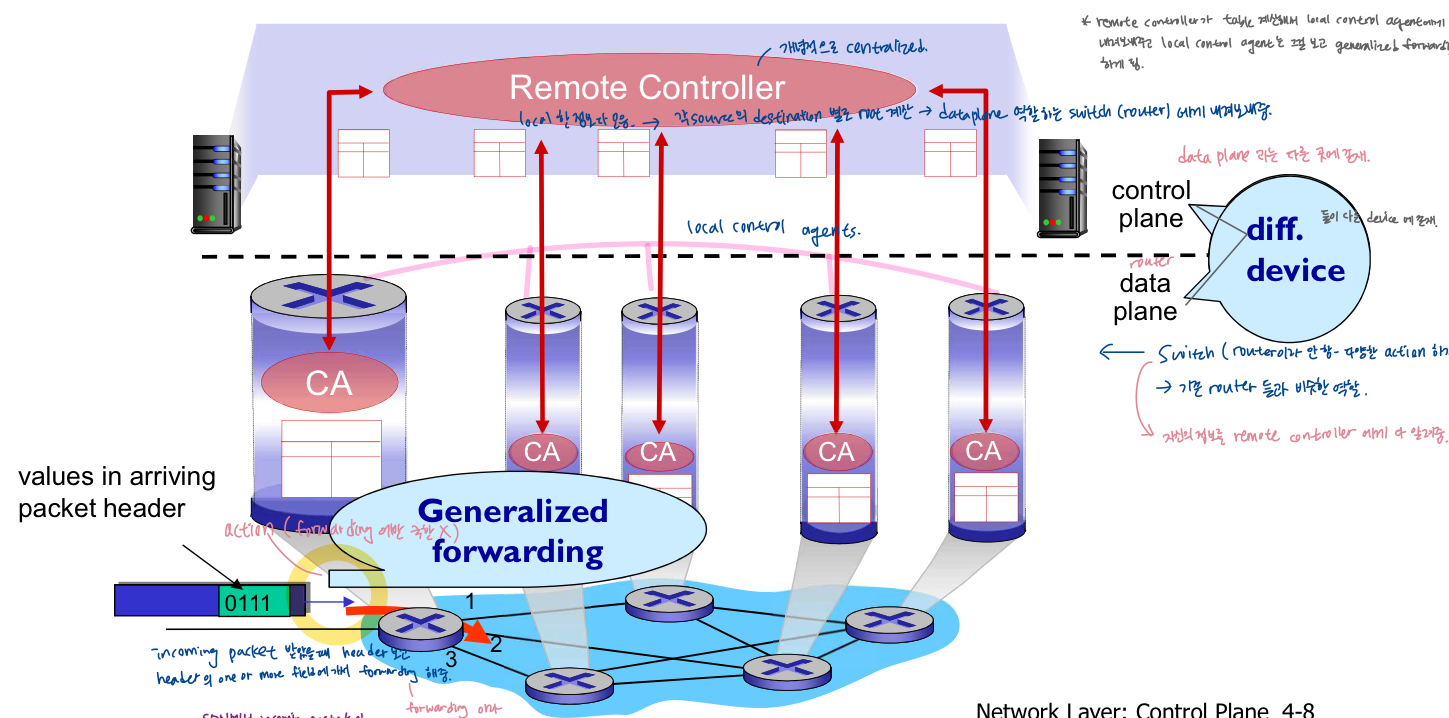
- software-Defined Networking(SDN) control plane
- centralized 원격 컨트롤러는 local control agents(CAs)와 상호작용하여 라우터에 포워딩 테이블을 계산하고 설치, network의 모든 router로부터 network의 상태정보를 끌어모은다.
- 원격 controller : 개념적으로 centralized, local한 정보를 다 모으고 각 source의 destination별로 root 계산-> dataplane 역할 하는 switch(router)에게 내려보내준다. 정보 collection -> 혼자 전체 이미지 앎.
- table 계산해서 local control agent에게 내려보내주고, local control agent는 그걸 보고 generalized forwarding
- control plane과 data plane이 다른 device에 존재.
- switch(다양한 action 하기 때문에 router이라 안 함) -> 기존 router들과 비슷한 역할, 자신의 정보를 remote controller에게 다 알려준다.
- SDN에서 incoming packet 받았을 때 forwarding table을 사용하는 traditional network에서는 look up&forward라 하는 것을 여기에서는 match(traditional router의 기능 포함, 하나 이상의 field를 match시킨 후 다양한 action 결정)&action이라 한다. header보고 header의 하나 이상의 field에 가서 action해줌.
- 원격 controller : 개념적으로 centralized, local한 정보를 다 모으고 각 source의 destination별로 root 계산-> dataplane 역할 하는 switch(router)에게 내려보내준다. 정보 collection -> 혼자 전체 이미지 앎.
- centralized 원격 컨트롤러는 local control agents(CAs)와 상호작용하여 라우터에 포워딩 테이블을 계산하고 설치, network의 모든 router로부터 network의 상태정보를 끌어모은다.

- routing과 forwarding 의 interplay (look up and forward)
- (RIB) routing information base가 forwarding information build 결정
- router은 control plane기능에서 routing protocal로 network 정보 끌어모아서 routing algorithm 적용 -> routing information base(forwarding information base로 계산-local forwarding table)가 만들어진다.
- 네트워크 계층 서비스 모델
- Q. 네트워크 계층(host to host delievery)은 transport 계층에 어떤 서비스를 제공하나요? 또는 sender에서 receiver로 데이터그램을 전송하는 '채널'에 대한 서비스 모델은 무엇인가요?
- A. 네트워크 서비스 모델은 송신 호스트와 수신 호스트 간의 e2e 패킷 전송 특성을 정의합니다. (reliable or unreliable하게 제공)
- transport 계층은 process to process deliever 제공. application msg에 대해 제공할 수 있는 서비스
- 가장 원시적인 core action : p2p, 추가로 connection을 establish해서 reliable하게 transfer or unreliable 하게 deliever or congestion control or flow control or timing support 등......
- network 계층도 마찬가지. host to host delievery 해 준다. + transport 계층이 내려보내는 segment를 deliever 해 주는 데 있어서 network 계층에서 제공할 수 있는 service 모델이 다양하다.
- transport 계층은 process to process deliever 제공. application msg에 대해 제공할 수 있는 서비스
- A. 네트워크 서비스 모델은 송신 호스트와 수신 호스트 간의 e2e 패킷 전송 특성을 정의합니다. (reliable or unreliable하게 제공)
- 개별 데이터그램에 대한 서비스 예시 : 보장된 전송(너가 나한테 전달 부탁하면 절대 drop하지 않고 전달해줄게), 지연 제한이 있는 보장된 전송(최대 ~범위까지 보장해서 전달해줄게. drop x는 보장 못해)
- 데이터그램의 흐름에 대한 서비스 예시(어떤 동일한 flow에 속하는 datagram들이 연이어 있는 상황) : in-ordered 데이터그램 전달(먼저 부탁-> 먼저 deliever), 보장된 최소 대역폭, 패킷 간 간격 변경 제한 (delay gitter : packet간 거리 ~이상은 안 되게 smooth하게 deliever)
- Q. 네트워크 계층(host to host delievery)은 transport 계층에 어떤 서비스를 제공하나요? 또는 sender에서 receiver로 데이터그램을 전송하는 '채널'에 대한 서비스 모델은 무엇인가요?


- best effort service 모델(너무 minimal한 service이지만 지금까지는 궁극의 승자였음, mechanism 심플, 어떤 경우에서도 계속 survive) :목적지까지의 성공적인 데이터그램 전송 보장 x, 전송 타이밍이나 순서 보장 x, end-end 흐름에 사용 가능한 대역폭 보장 x
- packet switching : datagram network , virtural circuit network(connection service, 마치 circuit이 있는 듯한 서비스 제공)
- circuit switching
- best-effort service에 대한 성찰
- 메커니즘의 단순성으로 인해 인터넷이 널리 보급될 수 있었음(local하게 적용된 사례가 있었지만 인터넷 전체에 보편적 service 모델이 되지는 x) - out of order, delay, bandwidth 문제 -> network 제공하는 회사들은 simple하게 해결. - congestion control
- telecom 회사 says 실제로 발생하는 traffic이 자기 resource 사용하는 것은 20~30%로 매우 낮음-> 보통 몰리면 문제 생기는데 overprovisioning하면 대부분 good enough 서비스를 제공해서 문제 감소!
- 충분한 대역폭 provisioning(사용자가 요청한 IT자원을 사용할 수 있는 상태로 준비) -> 실시간 애플리케이션(대화형 음성, 비디오)의 성능이 대부분의 시간동안 'good enough'. -> 많은 복잡한 문제 해결(out of order, bandwidth, gitter, delay문제)
- 처음에는 routing 잘 하려 했는데 결과적으로는 목적지 같으면 다 같은 길로 보냄 -> out of order 전달 거의 발생하지 x (나중에 전송한 packet 나중에 잘 도착)
- 복제된 애플리케이션 layer 분산 서비스(datacenters, content 분산 networks) 가 client network에 가깝게 연결되어 여러 위치에서 서비스 제공 가능.
- 아무리 overprovisioning 해 줘도 network volume이 너무 커지고 application이 너무 다양해지면 결국 'best effort service'만을 믿기는 힘들기에 이것 활용.
- poor CDN들도 web cache 덕분에 잘 살 수 O. 내 content가 popular해서 local하게 이 지역에서 많이 사용되면 local한 cache어딘가에 들어가 앉아있다.
- content provider들이 CDN distrubution network service 사면 (end user 가까운 곳에 살포) 자기 content를 거기에 다 upload한다.
- ex. 넷플릭스 구성 영화가 나라마다 다름 -> 네트워크가 most of time, good enough service를 폭발적으로 증가한 network scale에 맞춰 overproviding해주지 않아도 어느정도 app이 만족하는 service를 자체적으로 end 쪽에서 해줄 수 있는 infra.
- elastic(탄력적-TCP가 transfer, congestion control - badwidth garantee가 필요없는 서비스 ex. file transfer에 사용) 서비스의 혼잡 제어가 도움된다. - streaming data로 바쁘면 network congestion이 확 자기를 줄인다.
- 메커니즘의 단순성으로 인해 인터넷이 널리 보급될 수 있었음(local하게 적용된 사례가 있었지만 인터넷 전체에 보편적 service 모델이 되지는 x) - out of order, delay, bandwidth 문제 -> network 제공하는 회사들은 simple하게 해결. - congestion control
>> best effort service 모델의 성공에 의의 두기는 어려움 ~~
4.2 라우터 내부에는 무엇이 있을까?
- router : traditional routing에서 control plane과 data plane을 다 갖고 있으면서 forwarding, routing의 기능 다 해주는 장비
- end host: network 계층을 갖고 있지만 control plane x (routing 기능 x, dataplane 기능만 갖고 있음)
- router 내부 구성요소 : input ports, switching, output port, buffer management, scheduling

- control plane의 routing protocol에서 network 전체 상황을 파악하기 위해 protocal을 따라 control msg(routing msg) 를 주고받고, network wide logic이 적용되는 routing 알고리즘으로 RIB를 계산한다.
- IP Routing table(RIP)이 만들어진다.
- 이제 Data plane(forwarding plane)으로 넘어가서 IP Forwarding Table(FIB)에서 어느 output port로 뽑아줄지를 결정한다. *data plane에서는 user(application)의 data를 주고받음.

- Router architecture overview
- 일반적인 라우터 architecture에 대한 개략적인 view : 좀 더 추상적으로 그려보면 4가지의 구성요소가 있음.

- routing processor이 router과 management를 담당하는 control plane(software)이 된다. high-speed switching fabric은 data plane(hardware)이 된다.
- Input port functions
아무리 line speed로 동작해도 queue가 필요 : processing해서 output port로 보내기 위해서는 switch fabric에 넣어야 한다.

- Decentralized switching
- header field(destination. IP adress) 값 사용.
- 목표 : 'line speed'로 processing중인 input port 완성
- input port queuing : 데이터그램이 switch fabric으로 forwarding rate보다 빨리 도착하는 경우 (switch fabric이 충분히 빠르지 않은 경우 buffer overflow로 인한 입력 큐잉 지연 or 손실) - switch보다 line으로 들어오는 게 더 빠르면 queuing이 일어난다.
- Forwarding
- Destination-based forwarding : 목적지 IP주소만 기반(traditional router에서 일어남.)
- Generalized forwarding : 모든 header field 값 집합 기반(SDN에서 일어남.)
- (->input port)Switching fabrics(패브릭 전환)(->output port)
- 입력 버퍼에서 적절한 출력 버퍼로 패킷 전송
- switching rate : 패킷을 input에서 output으로 전송할 수 있는 속도
- N inputs : 바람직한 switching rate (N), times line rate(R)
- 종종 input/output line rate(NR)의 배수로 측정됨 - n개의 line에 packet이 몽땅 다 들어올 수 o. N대로 switching 해줄 수 있다면 전혀 input queue build up 이 안 되는 상황

- interconnection 네트워크를 통한 switching
- crossbar, clos networks, 기타 상호작용 네트워크는 처음에 multiprocessor의 processor을 연결하기 위해 개발.
- crossbar network : 입력 포트와 출력 포트가 서로 다른 여러 패킷을 병렬로 전달 가능
- 서로 다른 입력 포트에서 보낸 두 개의 패킷이 동일 출력포트로 향하는 경우 한 번에 하나의 패킷만 보낼 수 o -> 입력 버퍼에서 대기해야 함!
- Cisco 12000 : 상호 연결 통한 60 Gbps 스위치
- 서로 다른 입력 포트에서 보낸 두 개의 패킷이 동일 출력포트로 향하는 경우 한 번에 하나의 패킷만 보낼 수 o -> 입력 버퍼에서 대기해야 함!

- switching fabric이 취할 수 있는 구조 3가지(구조에 따라 switching speed의 구조적 한계점(제약) 생김)
- memory : 메모리 버스 타고 메모리에 저장
- memory bus 2번 지나야 input -> output 가능 , output port에서 memory bus를 타고 가져간다.
- memory bus를 input port가 이용하면 output port는 이용불가, 일단 메모리에 적힘 -> 메모리에 적힌 걸 output port가 읽어간다.
- memory를 input port에서 output port를 연결하려면 inputport에서 저장이 한 번 돼야 한다. -> 반드시 bus를 1번 타야 한다. -> memory bus가 빨라지면 빨라질수록 switching speed가 늘어나기는 하겠지만 memory bus를 2번 타야한다는 한계가 있다. (bus가 굉장히 빨라지면 switching speed가 늘어남)
- input port와 output port를 연결하는 독자적인 bus가 speed(접근속도)가 똑같다고 할 때는 언제나 'bus'가 'memory'보다 2배의 속도로 input port에서 output port로 전달
- bus : input port와 output port bus share
- 언제나 bus는 한 번에 한 port만 이용가능
- bus가 중간에 있어서 input port와 output port가 직접 연결, input port와 output port가 bus share, bus에 뜨는 내용을 볼 수 o. input port에서 도착한 것이 뜨면 output port에서 읽어간다. 전용 버스 한 번만 타면 바로 output port로 나간다.
- bus에 여러 데이터 --> 충돌발생 !!
- 전용버스 만듦 -> switching fabric의 속도를 line이 여러 input port, output port 쌍에서 동시에 갈 수 있게 해 줘야 switching fabric의 속도가 늘어난다.
- interconnection Network(3*3 crossbar)
- 한 번에 여러 개의 packet이 동시에 output port로 가게 하고싶다.
- 가장 간단한 형태. output port가 다르다면 동시에 switching 가능
- output port 다름 -> 타고가는 bus 다름-> 그래서 동시에 움직일 수 o but 동일한 output port 가려 할 때는 하나가 참아야 한다.
- 한계 : 서로 다른 input port에 도착한 packet이라 할 지라도 걔네가 향하고 있는 outputport가 같다면 그때는 버스에 겹치는 부분 생김(share해야 함) -> congestion 발생-> 동시에 움직이기 불가 -> 하나는 기다려야한다.
- memory : 메모리 버스 타고 메모리에 저장
- memory --> bus --> interconnection network 로 갈수록 속도제약이 점점 낮아진다.
- multistage switch : 여러 개의 작은 스위치로 구성된 다단계 스위칭
- 서로 다른 입력 포트의 패킷이 동일한 출력 포트로 동시에 진행되도록 허용 - 구성 intellegent하게 할 때

- 병렬성 활용
- 여러 switching 'planes'을 병렬(multiple switching fabric)로 사용하여 확장
- 입력포트와 출력포트(하나의 original packet이 오는 게 아니고 8개로 자른 것이 오게 됨 -> output port에서 걔네 다시 합침) 는 N개의 switching fabrics에 연결.
- 입력 시 fixed length cell로 datagram 조각화
- fabric을 통해 cell을 전환하고 종료 시 datagram 재조립
- 병렬처리를 통한 속도 향상, 확장
- Cisco CRS router
- 기본단위 : 8개의 switching planes
- 각 plane : 3단계(8개를 parallel하게) 상호연결 network
- 최대 100's Tbps switching 용량
- input port에 들어온 packet을 8개의 작은 조각으로 나눔 -> 8개의 switching을 통해 동시에 8개 내보냄
- 1개의 packet이 interconnection network통해 나가는 것보다 8배의 속도로 나갈 수 O (하나의 packet을 8개로 나누어 동시에 내보내기 때문에)
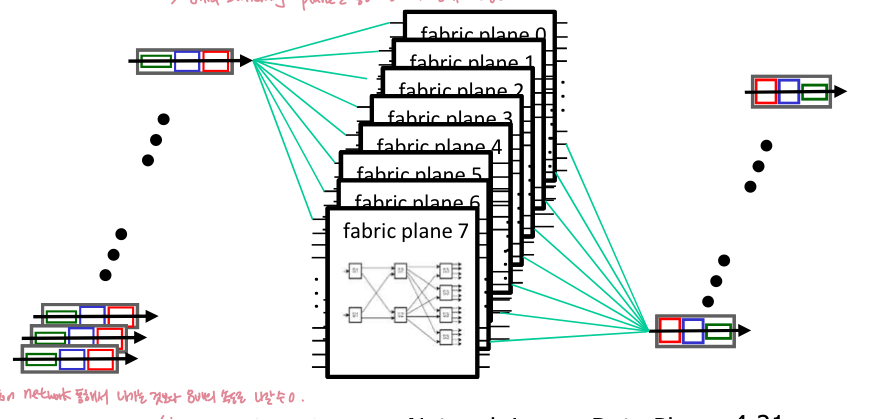
- Input port queueing & Head-of-the-Line (HOL) blocking
- input port보다 switch fabric이 느리면? -> input queue에서 큐잉이 발생할 수 있다. (cross bar 같은 경우 head of line blocking 발생 가능
* multistage interconnection network 사용하면 여러 inputport로부터 packet이 다 들어왔다고 하더라도 동시에 switching fabric 통과할 수 O.
* switching fabric의 속도가 input port -> switching port 밀어넣는 속도 당하지 못하면 -> input port에서의 queueing 발생
- HOL blocking : input queue 앞에 있는 대기 중인(queued) pocket(빨간색)는 대기열(queue)의 다른 pocket(초록)가 전진(forward)하지 못하도록 차단
- 차단된 pocket은 fabric을 통해 전송될때까지 기다려야 한다.
- 입력 대기열이 증가하여 입력 대기열에서 패킷 손실 발생 가능

- output port contention : 크로스바 스위칭 패브릭은 한 번에 하나만 패킷의 지정된 출력포트로 전송 가능 -> 빨간색 데이터그램(위쪽) 하나만 전송 가능

- one packet tione later : 녹색 패킷이 HOL blocking 경험
- 결과 : 녹색 outputport가 사용 가능하더라도 녹색 패킷은 1 packet time을 기다려야 한다.
- output port functions

- 스위치를 통한 도착속도가 output line speed를 초과할 때 버퍼링
- output port buffer overflow로 인한 queueing(delay) 및 loss
- egress queue에서 link로 뽑아줄 때
- Drop 정책 : 여유 버퍼가 없는 경우 어떤 데이터그램을 drop할 것인가?
- egress queue가 꽉 찼을 때 switching fabric에서 또 다른 packet이 들어오면 그 때 어떤 것을 drop할 것인가?
- 혼잡, 버퍼 부족으로 인해 데이터그램이 손실될 수 있음
- egress queue가 꽉 찼을 때 switching fabric에서 또 다른 packet이 들어오면 그 때 어떤 것을 drop할 것인가?
- Scheduling discipline : 큐에 대기중인 데이터그램 중 전송할 데이터그램을 선택한다.
- egress queue에 들어앉아있는 packet들중 어떤 애가 outgoing link를 사용할 수 있냐.
- 우선순위 스케줄링: 일반적으로 FIFO, 경우에 따라서는 우선순위 스케줄링, application이나 사용자별로 차별을 둔다.
- 최고의 성능을 얻는 것,
- 네트워크 중립성 (network neutrality) : 법안- 인터넷 사용자에게는 다 공정해야 한다.(차별성x)
- 우선순위 스케줄링: 일반적으로 FIFO, 경우에 따라서는 우선순위 스케줄링, application이나 사용자별로 차별을 둔다.
- egress queue에 들어앉아있는 packet들중 어떤 애가 outgoing link를 사용할 수 있냐.
- Drop 정책 : 여유 버퍼가 없는 경우 어떤 데이터그램을 drop할 것인가?



- 라우터의 버퍼링은 어느 정도일까?
- input port에서의 queueing보다 output port의 queueing이 더 어려울 수 O.
- queue 둬야 하는 이유
- input port : line speed와 switching fabric의 speed mismatch를 막기 위해 - multistage interconnection network를 이용하면 inputport queueing을 줄일 수 O. ( inputport에 들어온 모든 packet들을 동시에 한 packet time이내에 output port로 다 밀어낼 수 o.)
- output port : switching fabric의 speed와 outgoing link의 speed mismatch를 막기 위해 - 더 심각, 피하기 어려움. switching fabric이 굉장히 빨라서 link rate가 NR일 때 input port에서는 적재없이 한 번에 switching 기능.
- RFC 3439(buffer recommend) thumb 법칙 : 평균 버퍼링= '일반적인' RTT (250msec = 0.25초)에 링크 capacity C를 곱한 값. (buffer의 capacity = C * R ) ex) C = 10Gbit / link : 2.5 Gbit buffer(10Gbps * 0.25s) --> 크기 얼마로 할지 추천, buffer 이만큼 해 놓으면 drop이 발생하지 x!
- network에서 long fat pipe 연결하는 router : core에 있는 routers
- pipe는 sharing 일어남 -> multiplexing -> smooth out -> 한꺼번에 많은 packet이 link를 채우는 일 줄어들음
- 최근 권장사항 : (statistical multiplexing 효과 보기 위해 많은 수의 TCP flows(N)과 함께라면 buffering=

- window와 pipelining의 취지를 고려했을 때 long fat pipe일수록 pipe를 채우기 위해 pipe에서 동시에 달려오고 있는 packet의 수가 많을 수 o. 이 파이프를 share하고 있는 source destination pair가 많을수록 statistical 한 multiplexing효과때문에 traffic이 smooth out되니까 루트 N으로 나눠준다.
- network core에 있는 long fat pipe일수록 buffer을 더 크게 장만해야 한다.
- stop and wait 프로토콜 :송신자가 한 번에 하나의 패킷만 전송, 해당 패킷에 대한 ack가 돌아올 때까지 대기 -> 이 과정에서 링크에는 전송중인 패킷과 ack 한 쌍만 존재.
- stop and wait 하면 link의 효율이 낮아짐 -> window 둬서 pipelining(ack 받지 않은 상태에서도 윈도우 크기에서 여러 패킷을 연속적으로 전송 가능 -> 링크 대역폭 더 효율적으로 사용(최대량 : pipe가 꽉 찰 만큼) - 여러 source and destination 사이에 일어남.
- stop and wait 프로토콜 :송신자가 한 번에 하나의 패킷만 전송, 해당 패킷에 대한 ack가 돌아올 때까지 대기 -> 이 과정에서 링크에는 전송중인 패킷과 ack 한 쌍만 존재.
- network core에 있는 long fat pipe일수록 buffer을 더 크게 장만해야 한다.
- Buffer 관리

- policy
- drop policy : buffer가 꽉 찼을 때(queue가 꽉 차기 전에는 marking)
- scheduling policy : egress queue(output port의 queue)에서 다음번에 누가 link 차지해서 전송될 수 있게 해 줄건가?
- congestion이 발생했을 때 drop할 수도 있고 marking할수도 있음.
- drop : 추가할 패킷, 버퍼가 가득 차면 드롭하기
- congestion 발생하여 queue가 build up-> buffer가 full로 차고 추가적인 packet arrival이 발생했을 때 어떤 걸 drop하느냐?
- tail drop: 도착하는 패킷 드롭 - 가장 간단. arriving 한 packet을 없애버리기. 안에 있는 packet은 이미 도착해서 오래 기다린 애들
- proprity : 우선순위에 따라 drop/remove - priority 고려, queue에 있는 packet의 priority보다 arriving packet의 priority가 더 높다면 queue에 있는 prioirity가 낮은 걸 선택해서 걔네 drop하고 priority 높은 게 들어올 수 있게 한다.
- congestion 발생하여 queue가 build up-> buffer가 full로 차고 추가적인 packet arrival이 발생했을 때 어떤 걸 drop하느냐?
- marking : 혼잡을 위해 마킹할 패킷(ECN, RED)
- ECN(explicit congestion notification)
- IP계층에서 queue가 어떤 fresh order을 넘어서서 build up 되는 상황
- Congestion이 발생하겠다 해서 지나가는 packet의 IP header에 특정 bit(TOS field 2bit 사용) marking -> 목적지 host의 IP계층에서 TCP 계층에 IP datagram의 TOS에 적혀있었던 내용 notify -> TCP에서 packet에 대한 receiver가 sender 쪽으로 보내는 TCP segment 의 header에 2bit 사용해서 notify --> sender가 이 ECN에 의해 segment의 congestion을 표시하는 bit가 setting이 돼 있으면 loss가 없음에도 불구하고 rate를 줄여준다.
- IP계층에서 queue가 어떤 fresh order을 넘어서서 build up 되는 상황
- RED(random early detection)
- drop이 force되기 전에 선제적으로 action 취하기
- congestion이 발생할 것 같으면(congestion 미리 감지-> 임계치 넘어서, 어떤 threash hold 넘어가서 build up 됨.) serious한 정도에 따라 어떤 probability로 incoming packet drop 시킨다.
- 유연한 transport protocal 사용하는 application의 경우 : rate를 다 줄임-> 미리미리 congestion 피하기
- ECN(explicit congestion notification)
- Packet Scheduling
- 패킷 스케줄링: 링크에서 다음에 전송할 패킷 결정
- 선착순, round robin, 가중치 부여 공정 큐잉
- FCFS :도착한 순서대로 출력포트에 전송되는 패킷(FIFO라고도 함)
- priority scheduling:
- output port에 buffer가 조금 더 복잡하게 manipulate 돼야 함, 물리적으로는 buffer가 하나인데 이거를 정교하게 manipulate하거나 traffic을 priority로 classify하고 다른 클래스에 속하는 traffic은 다른 priority queue에 넣는다.
- 도착 트래픽 분류(header에 있는 field에 근거해서 하게 됨), 클래스별로 대기열 지정(class에 따라 buffer에서 다른 class의 queue에 집어넣게 됨) - 모든 헤더 필드를 분류에 사용 가능.
- Ex. source와 destination pair를 보고, 해당 사용자가 돈을 많이 내는 premium user라고 판단 -> 이러한 flow는 high priority queue에 넣어준다.
- delay-critical한 application에 대해 더 high priority를 주거나, 지나가는 packet의 header field를 보고 이 packet이 속한 traffic class를 구분한다. class에 따라 priority queue에 집어넣게 되고, link는 priority가 높은 queue가 비어 있지 않는 한 해당 queue에서 계속 링크를 사용할 수 있게 해 준다.
- highest priority queue가 비어 있을 때에만 그다음 highest priority queue에서 패킷이 나가게 되며, 이후에도 동일하게 priority 순서대로 link를 사용할 수 있게 된다. 동일한 priority queue 내에서는 FIFO 방식이 적용된다.
- 선착순, round robin, 가중치 부여 공정 큐잉
- 패킷 스케줄링: 링크에서 다음에 전송할 패킷 결정

- 버퍼링된 패킷이 있는 우선순위가 가장 높은 큐에서 패킷 전송 - 우선순위 클래스 내 FCFS

- scheduling policies: round robin
- Round Robin(RR)스케줄링(flexibility 떨어짐. 더 좋은 rate를 service해줄 방법 x)
- 도착 트래픽 분류(앞 priority queue 방식과 똑같음- packet들은 conceptually, 물리적으로 다른 class에 속하는 packet을 다른 class에 집어넣음, different traffic class에 대해 동일한 amount service rate 제공), 클래스별 대기열 생성 - 모든 헤더필드를 분류에 사용할 수 있음 --> priority가 높은 queue에서 계속 링크 사용할 수 있게 해줌
- 주기적으로 클래스 큐를 반복적으로 스캔 (queue가 비어있지 않다면 cyclic하게 각 traffic class queue에 앞에 있는 packet을 service해줌 -> 각 클래스에서 하나의 완전한 패킷(사용 가능한 경우)를 차례로 전송
- Round Robin(RR)스케줄링(flexibility 떨어짐. 더 좋은 rate를 service해줄 방법 x)


- Scheduling policies : weighted fair queueing
- 가중치 공정 큐잉(WFQ)
- traffic packets들을 traffic class로 나눠서 다른 queue에 집어넣는 것까지는 똑같음. but queue들은 서비스하는 rate가 다 다 동일하지 x
- 일반화된 round robin
- round robin을 generalize시킨 queueing 방식
- 각 class i에는 가중치 wi가 있고 각 사이클에서 가중치 서비스를 받는다.
- 가중치 공정 큐잉(WFQ)

- 최소 대역폭 보장(per-traffic-class)

- sidebar: 네트워크 중립성이란?
- 기술적측면: ISP가 리소스를 공유/할당하는 방식
- 패킷스케줄링과 버퍼관리가 메커니즘
- 사회적, 경제적 원칙
- 언론의 자유 보호
- 혁신, 경쟁 장려
- 강제적인 법적 규칙 및 정책
- 기술적측면: ISP가 리소스를 공유/할당하는 방식
- 국가마다 네트워크 중립성에 대한 '견해'가 다르다.
- 네트워크 중립성은 인터넷 서비스 제공업체(ISP)와 인터넷의 대부분을 규제하고 있는 정부가 인터넷의 모든 데이터를 동일하게 취급하고 사용자, 콘텐츠, 웹사이트, 플랫폼, 애플리케이션, 연결된 장비의 유형, 통신방법에 따라 차별하거나 요금을 차등부과하지 않아야 한다.
- 예를 들어, 이 원칙 하에, ISP는 특정 웹사이트나 온라인 콘텐츠에 대해 의도적으로 차단, 속도 저하, 또는 요금 부과를 할 수 없다. (인터넷의 모든 데이터를 공정하게. 다른 요금을 과금해서는 안됨)(우리 정서와 맞지 않는다는 이유로 blcck할 수 x. 법제화된다면 법적으로 금지)
- 유료 우선순위 x. 유료 우선순위 지정에 관여하지 않아야 한다.
- +기관 자체는 부시대통령 때 FCC기관 만들어서 마련. 오바마 때(2015년) open Internet protect, promote 위해 FCC에서 Network Neutrality 인정, 승인. 이어서 2015년에 lift
- 우리나라도 2020년에 법제화하려했는데 ISP들이 반발 -> 아직도 법제화 X
- 네트워크 중립성은 인터넷 서비스 제공업체(ISP)와 인터넷의 대부분을 규제하고 있는 정부가 인터넷의 모든 데이터를 동일하게 취급하고 사용자, 콘텐츠, 웹사이트, 플랫폼, 애플리케이션, 연결된 장비의 유형, 통신방법에 따라 차별하거나 요금을 차등부과하지 않아야 한다.
- 2015년 개방형 인터넷 보호 및 증진에 관한 미국 FCC는 합리적인 네트워크 관리에 따라
- 합법적인 콘텐츠, 애플리케이션, 서비스 또는 유해하지 않은 기기를 차단해서는 안된다.
- 합리적인 네트워크 관리에 따라 인터넷 콘텐츠, 애플리케이션 또는 서비스 또는 유해하지 않은 장치에 근거하여 합법적인 인터넷 트래픽을 손상시키거나 저하시키지 말아야 한다.
- 유료 우선순위 지정에 관여하지 않는다.
- Network layer : Interent
- host와 router(network 계층의 full functionality) 의 network layer functions(protocal 기능 살펴보기)
'CS > 컴퓨터네트워크' 카테고리의 다른 글
| [컴퓨터 네트워크] ch5. Network layer (5.1 | 5.2 | 5.3 | 5.4) (2) | 2024.12.07 |
|---|---|
| [컴퓨터 네트워크] chap4. Network Layer : The Data Plane ( 4.3 | 4.4 | 4.5) (1) | 2024.12.01 |
| [컴퓨터 네트워크] chap3. Transport Layer (1) | 2024.10.22 |
| [컴퓨터 네트워크] chap2. 애플리케이션 계층 (6) | 2024.10.21 |
| [컴퓨터 네트워크] chap1. Computer networks and the Internet (3) | 2024.10.10 |