5.1 개요
- 메모리를 통한 스위칭
- 1세대 라우터
- CPU가 직접 스위칭을 제어하는 기존 컴퓨터
- 패킷이 시스템 메모리로 복사
- 메모리 대역폭에 의해 속도가 제한(데이터그램 당 2개의 BUS 크로싱)
- 1세대 라우터
- 버스를 통한 스위칭
- 공유버스를 통해 입력포트 메모리에서 출력포트 메모리로 데이터그램 전송
- BUS contention(버스 경합): 버스 대역포에 의해 스위칭 속도가 제한됨
- 32gbps bus, Cisco 5600: 액세스 및 enterprise 라우터에 충분한 속도 제공
Q. 2400바이트의 데이터그램을 700바이트의 MTU를 가진 링크로 전송한다고 가정해보자. 원본 데이터그램에 식별번호 422가 찍혀있다고 가정하자 .몇 개의 조각영역이 생성될까? 조각화와 관련하여 생성된 IP 데이터그램의 다양한 필드값은 무엇인가?
A.
- 각 조각의 데이터필드 최대크기=680(20바이트 IP헤더가 있기 때문에). 따라서 필요한 조각의 수는 (2400-20)/680 =4
- 각 조각은 식별번호 422를 갖는다.
- 마지막 조각을 제외한 각 조각의 크기는 700바이트(IP헤더 포함)이다.
- 마지막 데이터그램의 크기는 360byte(ip헤더 포함)이다.(2400-20)-680*3=340
- 4개의 조각의 offset은 0. 85, 170, 255: 680/8=85
cs(circuit-switched networks), PS(packet-switched networks)
- VC NW(ATM)
- 엄격한 타이밍, 신뢰성 요구, 서비스보장 필요
- 네트워크 내부의 복잡성
- 멍청한 end system(telephone)
- Datagram NW(internet)
- 스마트 end system(컴퓨터)
- 적응, 제어, 오류복구 수행가능
- 네트워크 내부의 단순성, edge의 복잡성
- 탄력적 서비스, 엄격한 타이밍 요구사항 x - 최소한의(거의 없는) 서비스 보장
- 매우 이기종인 link-layer 기술을 사용하는 네트워크를 쉽게 상호연결할 수 있음
- 스마트 end system(컴퓨터)
Datagram networks
- 네트워크 계층에서 call setup x
- 라우터: 종단 간 연결에 대한 상태 없음
- 네트워크수준의 '연결'개념 x
- 각 라우터의 데이터그램 헤더 및 포워딩 테이블(FIB)에서 대상호스트주소를 사용하여 패킷 전달
Dual-stack: router들은 한 인터페이스에 IPv4/IPv6 주소를 둘 다 갖고 있음
Flow table abstraction
- 미들박스 및 링크계층 기능을 통합된 방식으로 제공하는 통합 접근 방식 -> 네트워크 전체 동작 프로그래밍 가능!
- 각 라우터에는 논리적으로 중앙집중화된 라우팅 컨트롤러에 의해 계산 및 배포되는 플로우테이블이 포함돼있다. (OpenFlow)

OpenFlow abstraction
- match + action 추상화: 모든 계층에서 도착하는 패킷헤더의 비트를 match시키고 action를 취한다.
- 일치하는 여러 필드(link, network, transport-layer)
- local action: drop, forward, modify, or matched packet을 컨트롤러에게 보낸다.
- network-wide 동작 프로그램
- 단순한 형태의 'network programmability'
- 프로그래밍 가능, 패킷별 'processing'
- 역사적 뿌리: active networking -> 통신 네트워크를 통해 흐르는 패킷이 네트워크의 작동을 동적으로 수정될 수 있게 하는 통신패턴
- 오늘날: 보다 일반화된 프로그래밍: P4
ISP: 통신서비스인가, 정보 서비스 제공자인가?
*규제 관점에서 보면 그 답은 정말 중요.
1934년과 1996년의 미국 통신법;
- Title 2: 통신서비스에 '공통 사업자 의무'부과: 합리적인 요금, 차별금지 및 규제 필요
- Title 1: 정보서비스에 적용
- 공통 통신사업자 의무 x(규제대상 x)
- 그러나 FCC에 "...기능 수행에 필요한 권한"부여
20세기-> 오늘날
20세기 phone net: intelligence/computing at network switches
Internet(pre-2005) : intelligence/computing at edge
Internet(post-2005): 프로그래밍 가능한 네트워크 디바이스, intelligence, computing, 거대한 application-level infrastructure(기반) at edge
인터넷의 아키텍쳐 원칙(세가지 기본 신념)
- 단순한 연결성
- IP프로토콜: 좁은 허리
- network edge에서의 intelligence, 복잡성
The end-end argument
- 일부 네트워크 기능(예: 안정적인 데이터전송, 혼잡)은 네트워크 또는 network edge에서 구현 가능
- 문제의 기능은 통신시스템의 end point에 있는 application의 지식과 도움을 통해서만 완전하고 정확히 구현, 통신시스템 자체의 기능으로 해당 기능 제공하는 것은 불가. (떄로는 통신시스템의 불완전 버전이 성능향상으로 유용할 수 o)
- low-level function 구현에 대한 위의 추론
Network 계층 control plane
- 목표: 네트워크 control plane의 원리 이해
- 네트워크 control plane을 구조화하는 두가지 접근방식
- 기존 라우팅 알고리즘(per-router control)
- 라우팅 알고리즘 분류
- link state 라우팅 알고리즘: Dijjkstra's 알고리즘 - OSPF
- 거리벡터 알고리즘: Bellman-Ford 알고리즘 - RIP
- 계층적 라우팅
- 라우팅 프로토콜
- RIP(초창기 사용), OSPF(현재 가장 많이 사용) / BGP
- 라우팅 알고리즘 분류
- SDN 컨트롤러(논리적 중앙 집중식 제어)
- OpenFlow, ODL, ONOS controllers
- 기존 라우팅 알고리즘(per-router control)
- 네트워크 관리, 구성
- internet control msg protocal: ICMP
- SNMP, YANG/NETCONF
기존 라우팅 알고리즘(목적지 기반 포워딩)
- 두 가지 네트워크 계층 기능
- data plane : Forwarding <-FIB(forwarding information base) : 라우터 입력에서 적절한 라우터 출력으로 패킷 이동
- control plane : Routing -> RIB(routing "): 소스에서 목적지까지 패킷이 이동하는 경로 결정- 한 host가 세상의 모든 host로 가기 위한 목적지 계산 -> 그 결과 저장
- routing의 결과물: routing table 만들기(=/ forwarding table : 나의 incoming으로 들어온 table을 어느 outputport로 뽑을거냐)
| 항목 | RIB | FIB |
| 역할 | 경로 계산 및 최적화 | 패킷 전달 |
| 포함 정보 | 모든 경로 정보 | 최적 경로만 포함 |
| 위치 | 소프트웨어 (제어 플레인) | 하드웨어 (데이터 플레인) |
| 속도 | 상대적으로 느림 | 고속 처리 |
| 업데이트 빈도 | 자주 변경됨 | 드물게 변경 |
Per-router control plane
- 모든 라우터의 개별 라우팅 알고리즘 구성요소는 control plane에서 서로 상호작용하여 forwarding table계산
- *forwaring table: 각 라우터들이 building -> router들끼리 routing protocal 통해 msg 주고받음. 주고받은 msg로 network의 view 갖게되고 view에 기반하여 routing algorithm을 돌려서 forwarding table.
- 목적지까지 데이터그램에 잘 전달되기 위해서는 network상의 모든 router들이 다 distributed table로 자신의 own forwarding table을 build했지만 이들이 orchestrate된 view 갖고 있어야 함 -> 그래야 consistent하게 목적지 향해서 datagram이 흘러갈 수 있음.
- individual routing algorithm comporent가 각 router에 다 들어가있음 -> 서로 interact
5.2 라우팅 알고리즘
routing algorithms
ㄴpath selection 알고리즘
routing protocol 목적: path 선택+ msg 포멧&action (network 상태 파악하기 위해서)
routing protocal 목적
- 라우터 네트워크를 통해 송신호스트에서 수신호스트까지 "좋은path(route)" 결정 - 좋은 path 어떻게 고를까?
- path: 주어진 초기 소스 호스트에서 최종 목적지 호스트까지 라우터 패킷이 이동하는 순서 - datagram이 경유하게 되는 sequence of router
- good : least cost(시간, 지불비용,,, 각 hope에 cost라는 property 붙어있으면 미니멈, least cost path 찾는 게 목적), fastest, least congested(network 사업자 입장: 자신의 source인 link router들이 골고루 잘 활용되게 하고 싶음 -> delay가 문제되지 않는 한 가장 덜 congest된 path를 통해가가게함 -> traffic 분산 -> network resource balance 사용)
- 일반적으로 minimum(least)-cost path나
- shortest path(링크 수가 가장 적은 경로) 의미
- -> 라우팅은 탑10안에 드는 네트워크 챌린지!
- router hope의 cost가 specific하게 매겨지지 않는 경우 -> shortest path(smallest link)거치는 path
- OSPF: 다양한 류의 cost를 router hope마다 매길 희망 가졌음. 대부분 인터넷 영역에서 host 1로 통일 -> shortest path찾는 routing 하고있음.
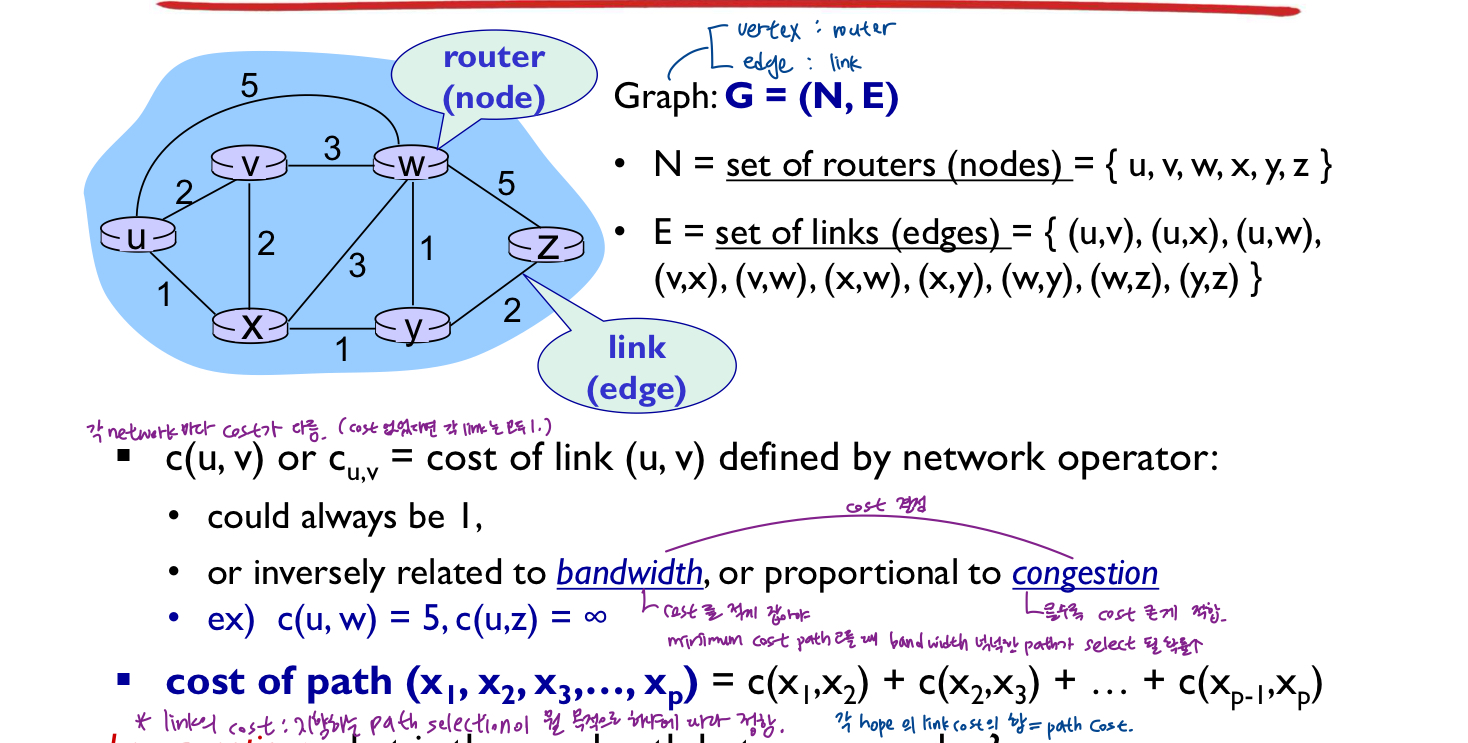
routing algorithm 분류
- global: 모든 라우터는 완전한 topology(연결성, 링크비용)정보를 갖고있다.
- "link state" 알고리즘 - 각 router가 네트워크 전체의 지도 갖고있음 -> 이걸 갖고 각자 route 계산
- 컴퓨터 네트워크에서 **토폴로지(Topology)**는 네트워크에 연결된 장치들(노드)이 물리적 또는 논리적으로 배치된 방식을 의미
<글로벌 혹은 분산된 정보?>
- 분산형: 반복되는 계산 프로세스, 이웃 라우터와 정보(네트워크의 다른 모든 노드에 대한 비용(거리)추정치) 교환
- 라우터는 처음에 물리적으로 연결된 이웃에 대한 링크 비용만 알 수 있음
- 거리벡터 알고리즘
- 이웃의 얘기를 듣고 route정함
- route점점 알아나감 : 처음에는 내 이웃에 뭐가 있는지 알고 걔네로 가는 link cost가 뭔지 금방 알 수 O.
- link 하나로 연결 -> 그 이웃으로의 path cost = link cost.
- 각 router은 자기 이웃을 앎. 한 router의 입장에서 보면 내 이웃들에 대한 상황을 내가 알고 있는데 이 router의 이웃이 자기가 알고 있는 이웃들에 대해 자기가 이러이러한 목적지 알고 있는데 나를 통해 지나가려면 이만큼으 ㅣcost가 든다고 말함. router의 지식이 한 번 iteration되면(이웃들의 얘기를 한 번 듣고 나면) 이 router가 발견하게 되는 목적지들이 늘어남 + 경로도 파악.
<경로가 얼마나 빨리 변경되나?>
- 정적(루트 cost자체가): 시간이 지남에 따라 경로가 천천히 변경됨
- manage protocal에 의해 특별한 event가 발생했을 때만 다시 계산(offline으로 계산할 수 있음)
- routing overhead가 훨씬 적고 route가 천천히 변한다는 특징 가짐
- 동적: 경로가 더 빠르게 변경
- linkcost에 변화 or link down됨 -> 네트워크 변화-> route selection으로 변화해야 함
- link cost로 어떤 matric 사용하냐에 많이 연결돼있음
- link 주기적 또는 촉발 update
- NW변경에 대한 대응-장점
- 링크가 up되고 down되는 건 dynamic 알고리즘 적용할 이유 별로 x(아주 rare해서)
- link cost자체가 available한 bandwidth라던지 level of congestion 이라던지 -> dynamic하게 link cost 변화-> 대응 사용
- network의 change에 대해 response하게 root 변경
- 충분히 빠르게, 내가 선택한 matrix의 change를 keepup할 수 있을만큼 periodic하게만 charge를 keepup
Routing 알고리즘 분류
- link state routing algorithm: Dijkstara's 알고리즘 - global -> 네트워크 topology 전체를 각 router가 다 알고있음(- OSPF(현재 인터넷에서 가장 유명)에서 사용됨
- Distance vector 알고리즘 : Bellman Ford 알고리즘 -> RIP, BGP에서 사용됨
- 계층적 routing
Dijsktra's 알고리즘
- 중앙집중식: 네트워크 토폴로지, 모든 노드에 알려진 링크비용
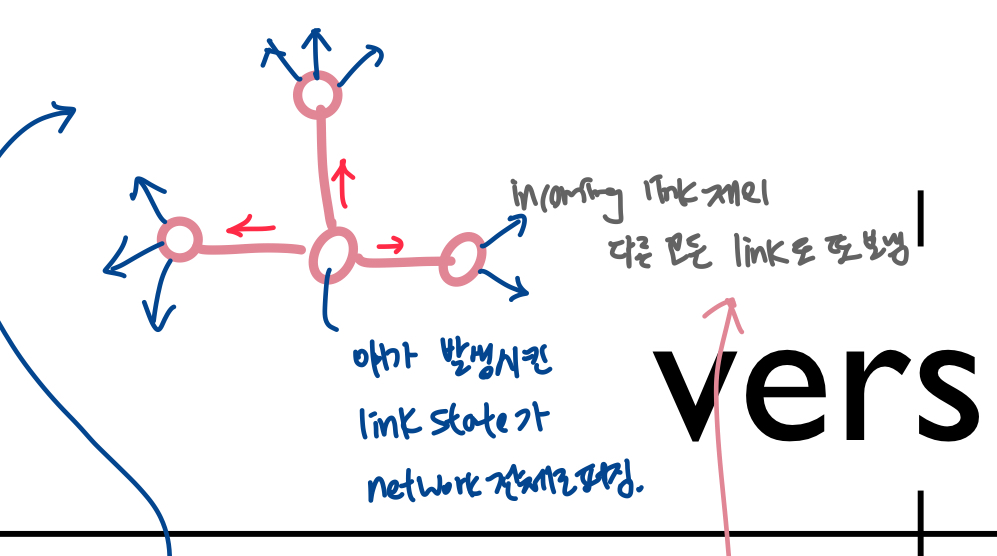
- 각 라우터는 자기를 source로 해서 다른 모든 node route 계산
- "link state broadcast"를 통해 달성- 각 router은 자기 주변의 link정도는 앎(내 이웃과 나 사이의 link의 cost 앎)-네트워크 전체의 topology(위성수학)
- 자기 바로 옆 link와 router 정보 broadcast -> 한 router 입장에서 내 주변꺼는 내가 알고, 나머지 애들이 broadcasting 한 정보이용 -> 네트워크 전체는 이렇게 생겼구나 알 수 o
- 모든 노드는 동일한 정보를 가짐
- 한 노드(소스)에서 다른 모든 노드까지 최소비용경로 계산 - 자기 자신을 source 로 해서 rest of router의 목적지로의 path를 그려야 함
- 해당 노드에 대한 포워딩테이블 제공- 자신의 forwarding table build up
- 반복적: k번 반복 후 k개의 목적지(k번째로 가까운 node로의 route 결정)로 가는 최소비용경로를 알 수 있음 - 각 router들의 입장 : 이 알고리즘 이용하면 각 router들은 자기를 source로 해서 모든 router or 목적지로의 루트 발견해야 하는데, 그러기 위해서 목적지 개수가 k개라면 k번의 iteration 거쳐야 함.
- 표기법:
- Cx,y : 노드 x to y에서의 direct link cost; direct link가 아니면 ∞(x,y사이에 링크 없으면)
- D(v): 소스에서 목적지 v까지의 최소비용경로의 현재비용 추정치
- p(v): 정점v에 도달하기 위해 최단경로에서 바로 앞에 위치한 정점(노드)를 나타낸다. v로 가는 최단 경로를 역으로 추적할 때 사용하는 직전노드
- N': 최소비용경로가 확정적으로 알려진 노드 집합 - shortest path가 확정된 node들의 집합

example
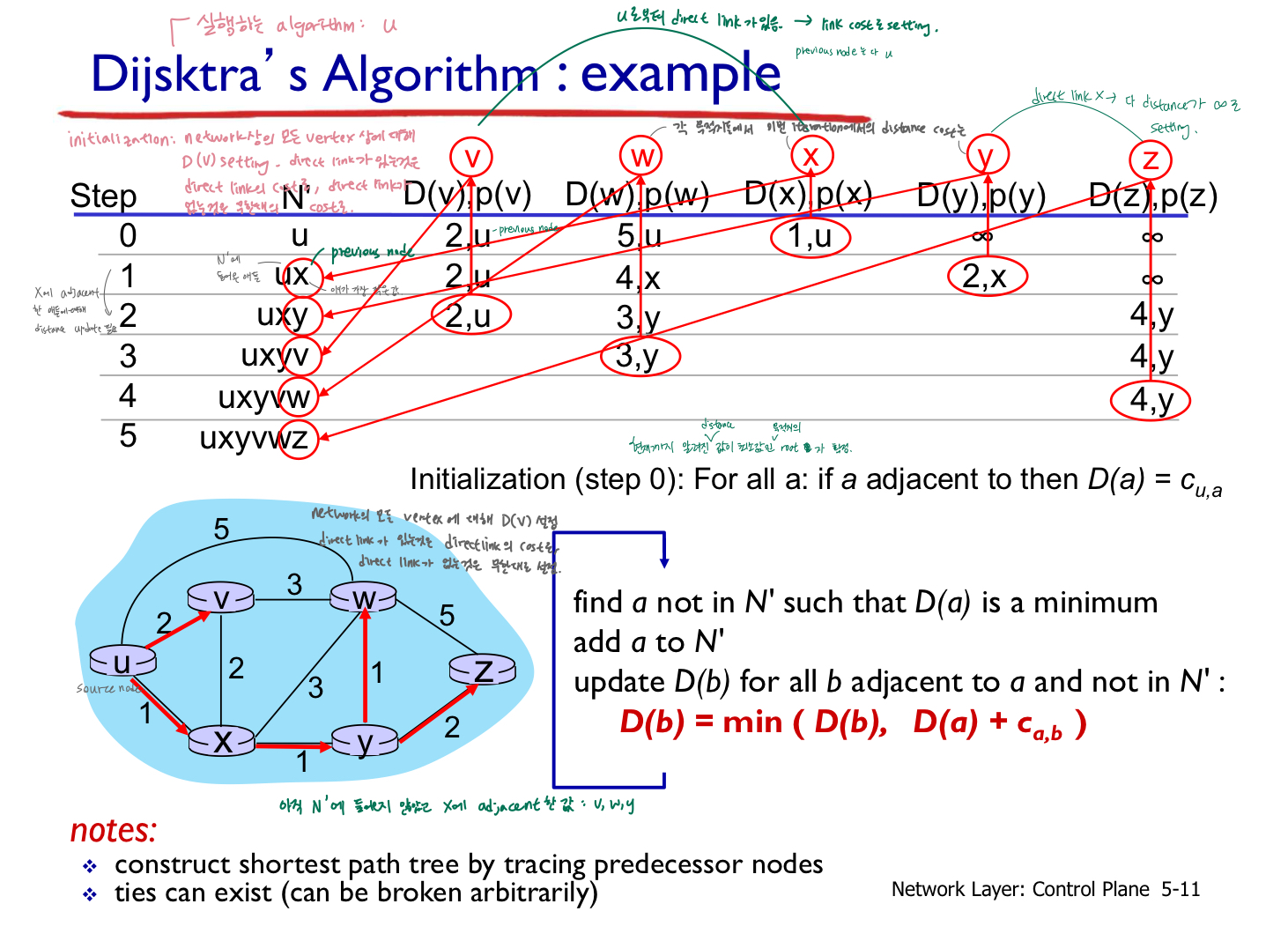
- notes
- 이전노드를 추적하여 최단경로트리 구축
- 동점이 존재할 수 있음(임의로 끊을 수 있음)
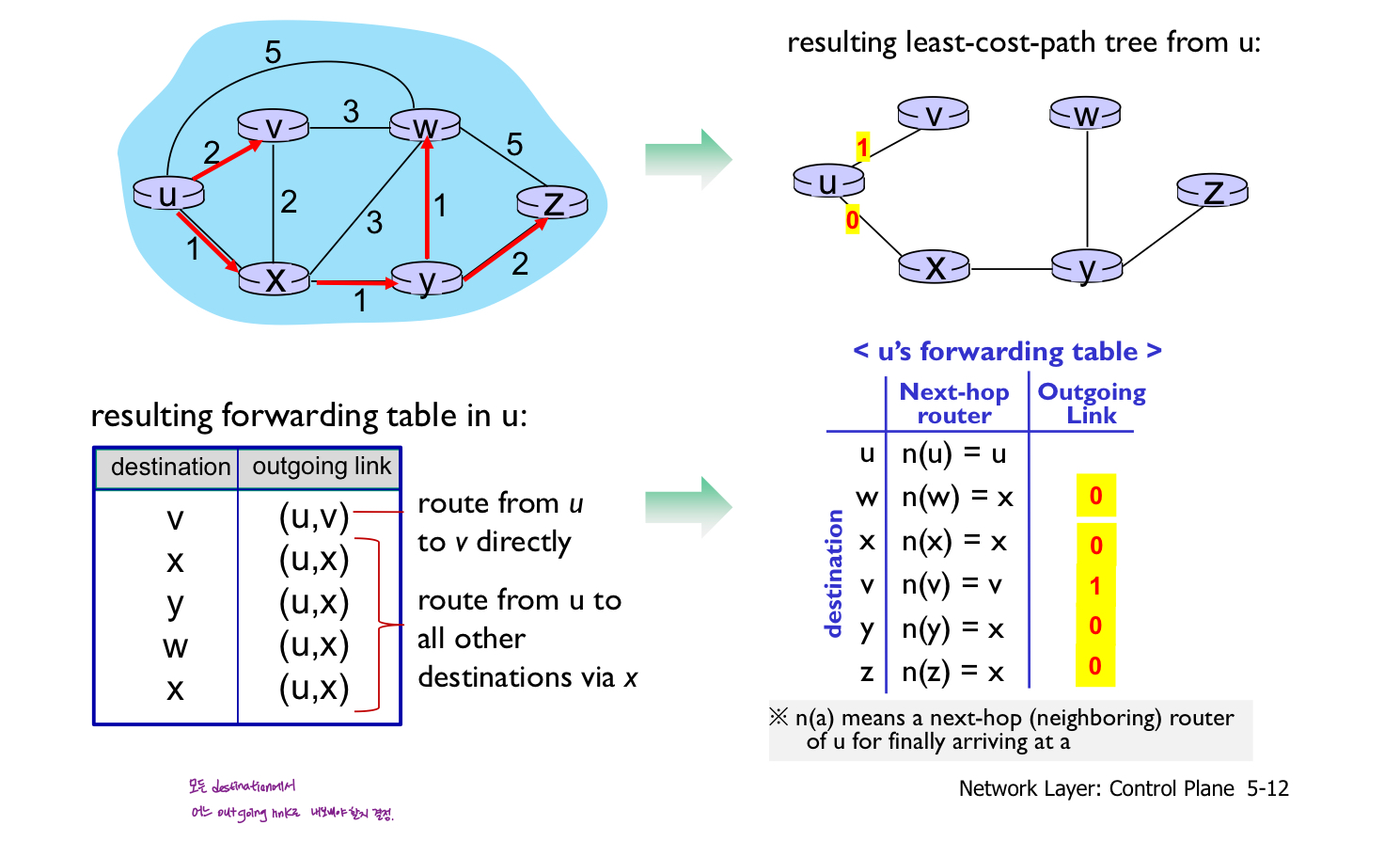

Q. 다음 네트워크를 고려합니다. 표시된 링크 비용으로 Dijkstra의 최단경로 알고리즘을 사용하여 x에서 모든 네트워크 노드까지의 최단경로 계산하시오. 아래 표를 계산하여 알고리즘이 어떻게 작동하는지 보여주시오.

Dijkstra의 알고리즘: 토론
- 알고리즘 복잡성: 주어진 n개의 노드 (소스 포함하지 않음)- iteration n번
- 각 n개의 반복: 모든 노드를 확인해야 함,w는 N'에 없음
- n(n+1)/2 비교 : O(n^2) 복잡성- n+ (n-1)+ (n-2) ...1
- 힙을 사용하면 더 효율적인 구현 가능 ; O(nlogn)
- 메시지 복잡성
- 각 라우터는 링크상태 정보를 다른 n개의 라우터에 브로드캐스트 해야함
- n개의 노드, E개의 링크, O(|n|.|E|)개(msg의 complexity)의 메시지 전송 - n: 목적지의 개수(node), E: network상 edge의 개수 - 여기에 비례해서 complexity 증가. - edge 개수가 많아지면 많아질수록, 목적지가 많아질수록, node가 많아질수록 node들에게 edge정보가 다 broadcasting 해야 하니까 msg complexity 높음
- 효율적인 (그리고 흥미로운)브록드캐스트 알고리즘 : O(n) 링크 교차로 하나의 소스에서 브로드캐스트 메시지 전파
- 각 라우터의 메시지 교차 링크 수 : 전체 메시지 복잡도 : O(n^2)
- 특징:
- 글로벌 정보 사용
- 선택된 경로에서 루프 없음
- 음수가 아닌 cost 사용
- root 계산에 loop가 없는 path 결정가능
Dijkstra 알고리즘의 문제
- 링크 비용(traffic volumn에 의해 결정될 때)이 트래픽 양에 따라 달라지는 경우 경로 진동이 가능(route oscillations)
- -> 사용하지 않는 게 해결방안 아님. 사용하더라도 herd effect 피하기 -> random하게 (시간차를 두더라도 syncronozed되기 때문에 아예 random하게!)
- 가정:
- 링크비용= 전송 트래픽 양(트래픽 양에 따라 달라짐)
- 링크 비용은 대칭적이지 않음(방향성)
- B와 D는 1단위의 트래픽을 A로 전송하고 C는 e단위의 트래픽을 A로 전송
- 처음에는 약간 불균형한 경로로 시작
- 모두가 가장 적은 부하를 가진 경로로 이동하여 다음번에 가장 많은 부하를 받도록 하여 모두가 switch함
- -> 무리짓는 효과(Herding effect) -> 막기 위해서는 link state advertise : 각기 다른 시점에 asymetric하게 router들이 자기 link state 갖다가 동기화된 시간에 딱딱 발생시키지x - 처음에 다 다른 시간에 발생시킴 - 실질적으로 network 운영하다보니 처음에 그렇게 한다해도 시간이 좀 더 가다보면 이들이 syncronized된 시점에 route advertise 하게 된다. -> herding effect 피할 수 없음 ㅜㅜ
- 동적 부하 정보를 사용하는 모든 라우팅 프로토콜에서 발생가능

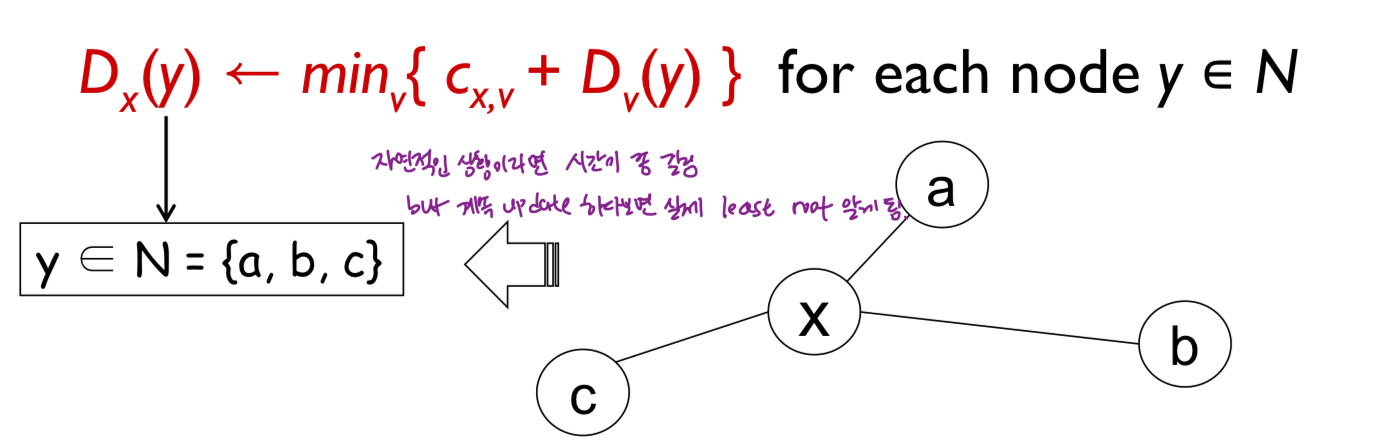
Distance vector(DV) 알고리즘
- Bellman-Ford(BF) 방정식에서 비롯(동적 프로그래밍)
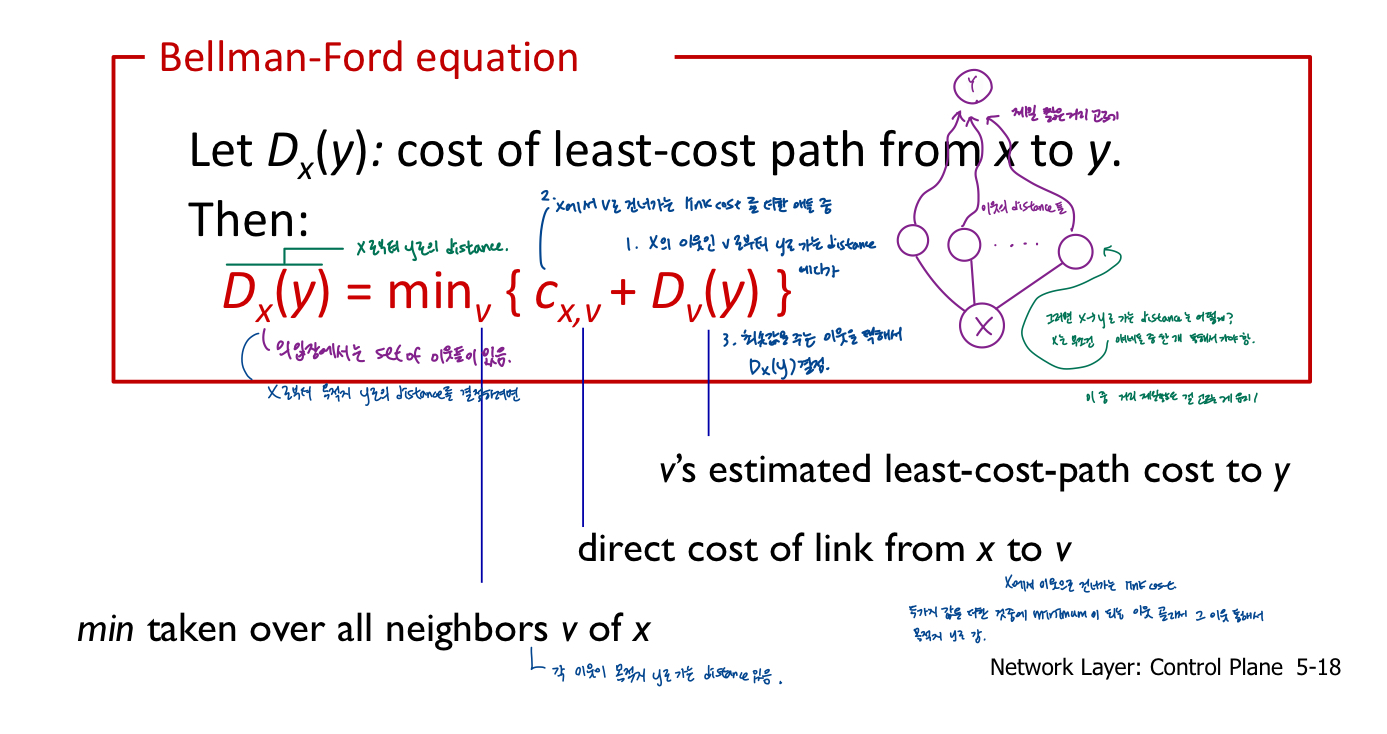
- u의 이웃노드인 x,v,w가 목적지 z에 대해 알고있다고 가정
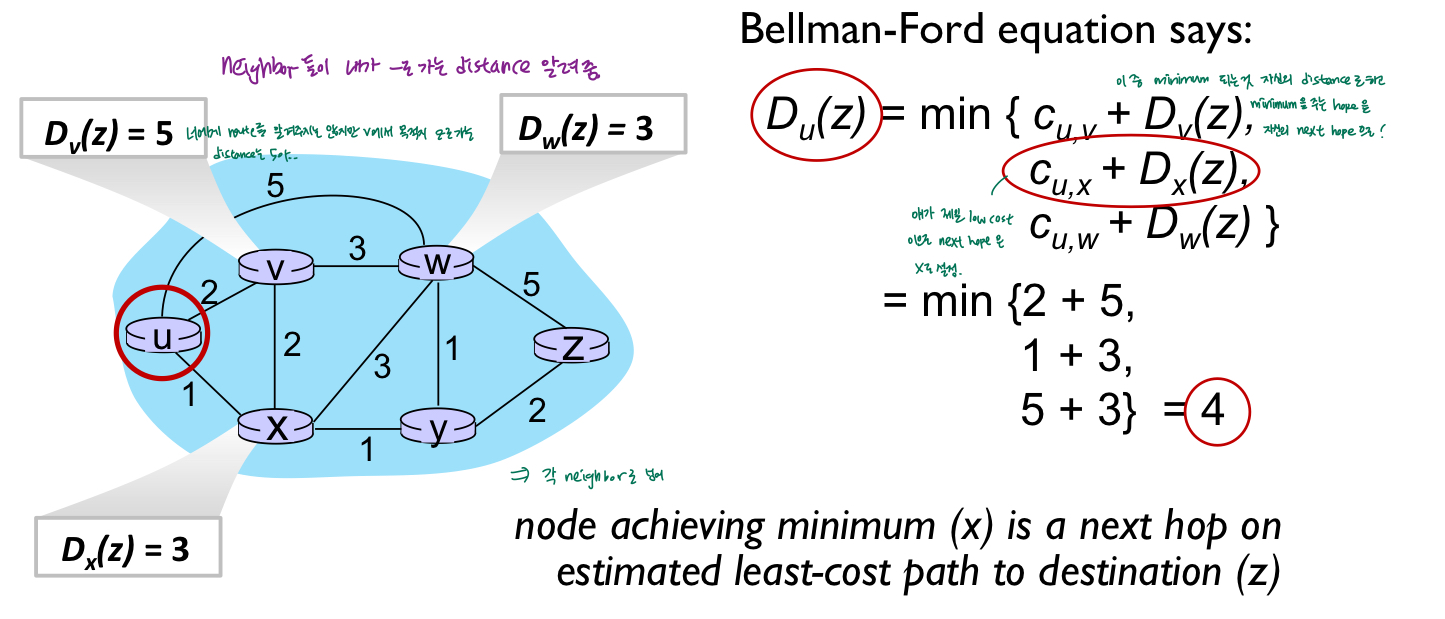
- DV 알고리즘
- key idea
- 각 node가 자신의 network상에서 알 수 있는 모든 목적지의 distance vector을 이웃에게 알려줌. 각 node는 이웃의 distance 정보 이용해서 자신의 node 정보 update. -B-F 방정식 이용
- 각 노드는 때떄로 이웃노드에게 거리벡터 추정치를 보냄
- 이웃노드로부터 새로운 거리벡터 추정치를 받으면 B-F방정식을 사용하여 자신의 DV 업데이트
- x가 목적지 y로 가는 distance vector 이용해서
- key idea
- 소인수, 자연 조건(자연적인 상황이라면 시간 걸림), 추정치 Dx(y)는 실제 최소비용 Dx(y)에 수렴(궁극적으로 실제의 least cost를 발견한다.)
DV 알고리즘
- 각 노드(과정 순서대로 반복): 계속 looping -> 네트워크 전체의 distance vector가 점점 converge(원래 그랬어야 하는 값으로):
- 대기(로컬 링크비용 변경(나의 목적지 distance를 갖고 있다고 할 때 각 node는 change있을때를 기다림) 또는 이웃으로부터의 메시지) - 나의 distance vector 변화할 겨우 생김
- change 발생 : 나의 local link cost 변경, neighbor로부터 neighbor의 distance vector을 새롭게 받았을 때 -> 둘 중 하나 발생해도 내 distance vector가 변경될 수 있는 chance
- 이웃으로부터 받은 DV 사용하여 DV추정치 다시 계산 : 변화 있었으면 distance vector 새로 계산
- 목적지에 대한 DV가 변경되면 이웃에게 알림 - 내 이웃에게 말했던 걸로 변경했기 때문에 다시 알려야 함
- 하지만 아무런 변화 없다? 내 이웃에게 굳이 다시 안 알려도 됨
- 대기(로컬 링크비용 변경(나의 목적지 distance를 갖고 있다고 할 때 각 node는 change있을때를 기다림) 또는 이웃으로부터의 메시지) - 나의 distance vector 변화할 겨우 생김
- 반복적 (각 노드가 자신의 거리벡터를 recomplete하는 시점 다 다름) , 비동기(자신의 distance vector 계산, 각 노드마다 다른 시점에 발생) : 각 로컬반복은 다음에 의해 발생
- 로컬 링크 비용 변경
- 이웃으로부터의 DV 업데이트 msg
- 분산(각 노드가 자신의 거리벡터를 recomplete하는 시점 다 다름), 자체 중지(네트워크 상황 일정하게 유지 -> self stopping) : 각 노드는 자신의 DV가 변경될 때만 이웃노드에게 알림
- 이웃노드는 필요한 경우에만 이웃노드에 알림
- 알림을 받지 못하면 아무런 조치도 취하지 않음
- self stopping : link cost도 변경되지 않음. 이웃으로부터 오는 distance vector도 x. 더이상 새로운 distance link를 generate하지 x.
- 모든 라우터들이 다 이런 상태? 잠정적으로는 distance vector가 현재 settle돼있는 상태로 가게 됨.
- 네트워크 어느 지점에서 링크비용 변경되면 다시 그 링크비용이 변경된 그 router가 자신의 네트워크 어느 지점에서 링크비용이 변화되는 일이 발생하면 다시 link cost가 발생한 그 router가 자신의 distance vector을 새롭게 계산 -> 자신의 distance vector에게 변화 생기면 이걸 자신의 이웃에게 할림 -> 물결처럼 네트워크 전체에 소문이 퍼져나감
- 이웃노드는 필요한 경우에만 이웃노드에 알림
DV 예시: 반복
*예시는 굿노트 피피티로 보기~~

- 반복적 통신: 계산단계가 네트워크를 통해 정보를 확산
- t=0
- t=0에서 c의 상태는 c에만 있다.
- t=1
- t=0에서 c의 상태가 b로 전파되어 최대 1홉 떨어진 거리에 벡터 계산에 영향을 줄 수 있다(즉, b에서).
- 1 hope away 인 neighbor들에게 퍼져나감
- t=2
- t=0에서 c의 상태는 이제 최대 2홉 떨어진 거리 벡터 계산에 영향을 줄 수 있다.(즉 b에서 이제 a,e에서도)
- 2 hope away인 neighbor들에게 퍼져나감
- t=3
- t=0에서의 c 상태는 최대 3홉 떨어진 곳(즉 b,a,e에서 현재 d,f,h에서도) 거리벡터에 영향 미칠 수 있음
- t=4
- t=0의 c상태는 최대 4홉 떨어진 곳(즉 b,a,e,c,f,h에서 현재 g,i에서도)의 거리벡터 계산에 영향을 미칠 수 있음
- t=0
DV : link cost changes
- 링크비용 변경
- 거리벡터 새롭게 계산-> 변화생기면 이웃에게 알림
- 내 옆에서 발생 ->나의 거리벡터 새로 계산
- good news(4->1): 굉장히 빨리 퍼져나감
- bad news(1->4): 굉장히 slow하게 반영
- 내 옆에서 발생 ->나의 거리벡터 새로 계산
- 노드는 로컬 링크비용 변경 감지
- 라우팅 정보 업데이트, 로컬 DV를 다시 계산
- DV가 변경되면 이웃에게 알림
- 거리벡터 새롭게 계산-> 변화생기면 이웃에게 알림
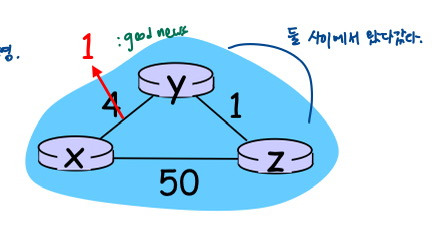
- 좋은소식은 빠르게 전달
- t0: y는 링크비용 변화를 감지하고 자신의 DV 업데이트, 이웃에게 알림(굉장히 빨리 빠져나감)
- t1: z는 y로부터 업데이트 수신, 자신의 테이블 업데이트, x에 대한 새로운 최소비용을 계산하여 이웃에게 DV보냄
- y의 업데이트 받아서 자신의 거리벡터 업데이트, -과거에는 z->x:5, 현재는 z->x:2
- t2: y 는 z의 업데이트( y는 이미 이것을 반영해서 자신의 거리벡터 업데이트-> 받더라도 영향 x)를 수신하고 거리테이블 업데이트.( y의 최소비용은 변경되지 않으므로 y는 z에게 메시지를 보내지 않는다.
링크비용 변경으로 인한 DV의 결함; 무한대까지 계산링크비용 변경

- 링크비용 변경:
- 노드는 로컬 링크비용 변화를 발견
- 나쁜 소식은 느리게 움직임 - "무한대까지 계산"
- 알고리즘이 안정화되기까지 44번 반복(y랑 z가 x로 가는데)
- sol1
- y는 x에 대한 direct링크의 새로운 비용이 60이라고 생각하지만 z는 5라고 생각
- y와 z가 x로 가는 게 오래걸리게 됨 -> y를 거치지 않고 z를 통해 가는 게 더 빨라짐
- 따라서 y는 "x에 대한 나의 새로운 비용은 z를 통해 6이 될 것이다"라고 계산, x에 대한 새로운 비용 6을 z에 알림
- y는 z가 'x까지 5만에 갈 수 있다'고 한 것 기억 -> 직접 가지말고 z를 통해 가야겠다!
- z는 y를 통해 x로 가는 경로에 새로운 비용 6이 있다는 것을 알게 되므로 z는 "x로 가는 나의 새로운 비용은 y를 경유해 7이 될 것이다"라고 계산하고 x에 대한 새로운 비용 7을 y에게 알림
- y는 z를 통해 x로 가는 경로에 새로운 비용 7이 있다는 것을 알게 되므로 z는 "x로 가는 나의 새로운 비용은 y를 경유해 8이 될 것이다"라고 계산하고 x에 대한 새로운 비용 8을 y에게 알림
- z는 y를 통해 x로 가는 경로에 새로운 비용 8이 있다는 것을 알게 되므로 z는 "x로 가는 나의 새로운 비용은 y를 경유해 7이 될 것이다"라고 계산하고 x에 대한 새로운 비용 9을 x에게 알림 -> 50 넘을떄까지 count해야 깨달음
- y는 x에 대한 direct링크의 새로운 비용이 60이라고 생각하지만 z는 5라고 생각
- sol2
- z에게는 x로 가는 next hope이 y이기에 y에게는 나는 x로 가는 길 무한대야~라 말함 -> y가 z를 통해 x로 가려는 시도x
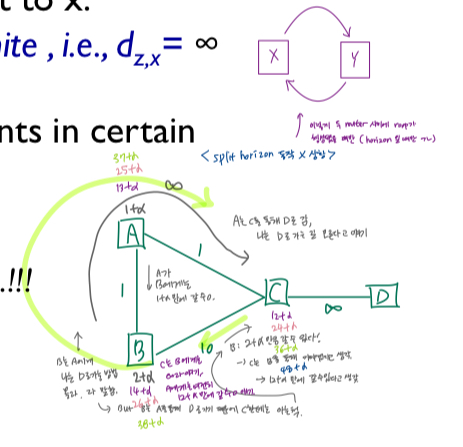
다음 홉이 B인 경로 정보를 다시 B로 보내지 마세요!
- sol1) 수평선 분할
- 노드A는 C에 대한 경로(즉 A에서 B에서 C로)를 B에 다시 알리지 않는다.
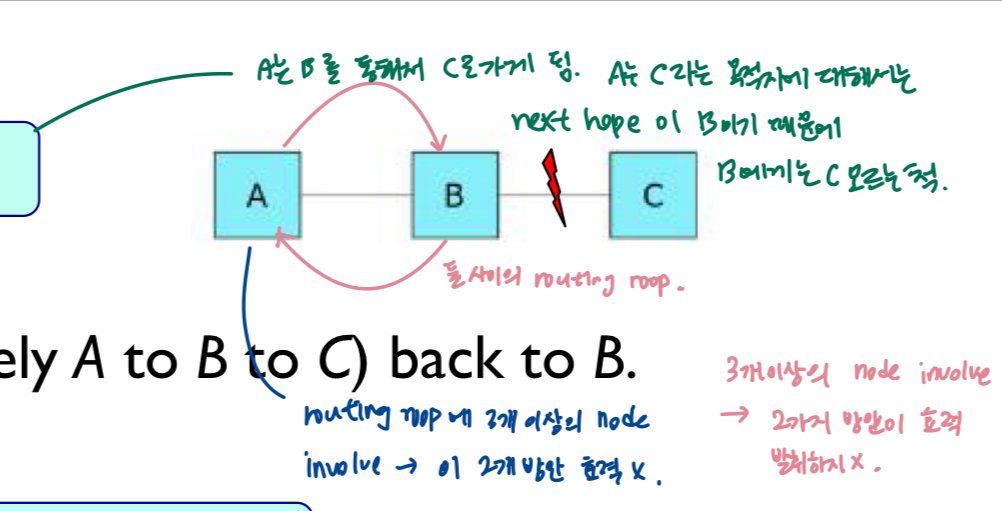
다음 홉이 B인 경로정보의 비용을 B까지 무한대라고 말하고다니세요!
- sol2)(업데이트) poisoned reverse 분할 지평선 - 나는 c로 가는 것이 무한대야 라고 말함. 아예 자신의 distance vector에서 c를 제거하는 대신, A는 C로 가기 위한 다음 홉이 B라면 B에게는 '나는 C로 가는 길이 무한대야' 라고 말함.
- 노드 A는 C에 대한 경로를 B까지 도달할 수 없는 무한대 경로로 알린다.
- 이전 예제에서 z가 y로부터 x에 도달하기 위한 경로를 업데이트 받으면
- z는 y(y는 x에 도달하기 위한 다음 홉)에게 x까지의 거리가 무한대라고 알려줌(즉 dz,x = 무한)
- 따라서 y는 z를 경유해서 x에 route하지 않을것임
- 상당히 일반적인 특정 네트워크 토폴로지에서 라우팅 알림의 크기를 크게 늘릴 수 있음
- 이렇게 하면 무한대까지 세는 문제가 완전히 해결되나요?
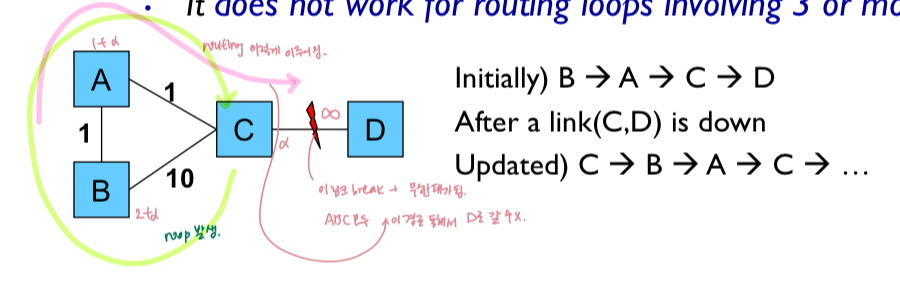
- 3개 이상의 노드가 포함된 라우팅 루프에서는 작동하지 않음!
| LS(link state) | DV(distance vector) | |
|
|
|
| 메시지 복잡성 |
|
|
| 수렴속도 | - O(n^2)알고리즘 : straightforward한 알고리즘[n+(n-1)+...+2+1] -shortest path 찾으려면 n번의 iteration, 각 iteraition에서 하나씩 노드가 N'로 옮겨가니까. -smart하게 사용 : O(nlogn) - 다양한 cost 값때문에 진동 가질 수 있음- 동적으로 host 값을 사용하는 경우가 아니라면. ㄴ동적으로 traffic amount 반영하는 cost값 사용 : 경우에 따라 진동 발생가능(herding effect때문에)- 이게 아니라면 O(n^2)로 확정 |
- msg에서 distance vector가 얼마나 왔다갔다해야 궁극적으로 route 수렴이 일어나냐 했던거랑 같은 논리 -route확정시간 확실하지x-> 어려움 겪음 -수렴시간 다양 - 라우팅 루프일 수 있음 - dv를 set of router들이 계속 counting to ∞ - count -to- infinity 문제 |
| 견고성 : 라우터가 오작동하거나 손상되면 어떻게 되나? |
ㄴ얘를 거쳐가면 문제 있을 수 o 하지만 나머지 malfunction 거쳐가지 않는 애들은 영향x 그러나 하나의 링크 상태 노드는 자신의 포워딩 테이블만 계산하기 때문에 링크 상태 알고리즘에서 경로 계산은 어느 정도 분산되어 수행된다. 따라서 링크 상태 알고리즘은 어느 정도의 견고성을 제공한다. |
따라서 거리 벡터 알고리즘을 사용하는 네트워크에서 한 노드의 잘못된 계산은 전체로 확산될 수 있다. - -물결처럼 전체로 퍼져나감 -자신의 링크 값을 엉터리로 얘기할 수 있음 -각 라우터가 모든 목적지에 대한 거리벡터를 알려서 네트워크 전체에 알림 -> 모두에게 영향미침 |
5.3 인터넷에서의 AS내부라우팅
Hierarchical routing
확장 가능한 routing 만들기
- 지금까지의 라우팅 연구- 이상화
- 모든 라우터가 동일
- 네트워크 "flat" - 실제로는 계층적
- 확장성의 문제: 한 링크 state가 전체로 퍼져나가야 함 -> 커짐
- --> 실제로 그렇지 않을 수 있음
- 확장성: 수십억개의 목적지 포함
- 모든 목적지를 라우팅 테이블에 저장할 수 없음
- 라우팅 테이블 교환은 링크를 휩쓸것이다!
- LS : 네트워크 스케일이 커지면 커질수록 (|n|이 커질수록) |E| 커짐 -> O(n^2)커짐 -> 확장성x
- DV : 인터넷에 있는 수많은 서브넷에 의해 다 거리값 실려야 함
- 거리벡터사이즈 엄청나게 커짐. 라우터가 유지해야 하는 라우팅 테이블의 entry도 엄청나게 높아짐
- DV : 인터넷에 있는 수많은 서브넷에 의해 다 거리값 실려야 함
- 관리 자율성:
- 인터넷: 네트워크의 네트워크
- 네트워크 관리가 라우터 세트에 대해 다름
- 각 네트워크 관리자는 네트워크 내부 조직의 측면을 외부로부터 숨기기 위해 자체 네트워크에서 라우팅 제어 가능 - 자신의 내부 네트워크에 대해 외부에 알리고 싶지 x, 모든 라우터가 flat하게 LS 혹 DV 주고받는 건 말이 안 되는 접근
- LS DV : 인터넷에 전체가 얘네를 flat하게 적용하는 것은 어려움
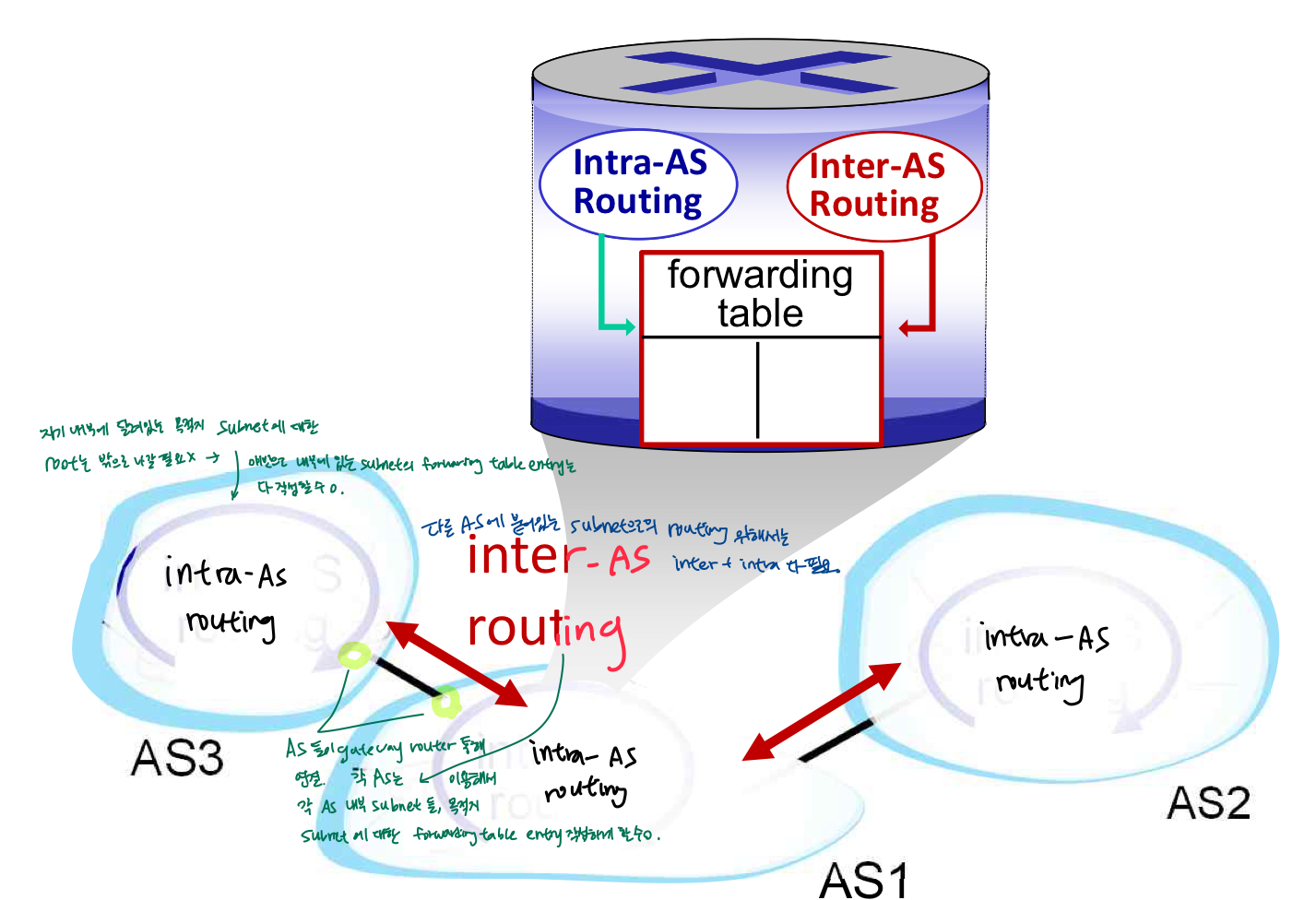
계층적 라우팅: 자율 시스템(AS)
- 라우터를 AS(일명 "도메인" , 인터넷에 있음, 같은 routing policy 제공하는 네트워크의 집합)으로 알려진 지역으로 집계
- 일반적으로 단일 소유권 및 관리 제어 하에 있음 - 서로 linkstate 다 알리고 감추지x. LS나 DV 하나 정해서 적용.
- 고유한 32비트 정수 AS번호(ASN)으로 식별 - 각 AS에 붙여지는 32bit unique ID
- ASN은 인터넷 할당번호기관(IANA)에서 관리. IANA(여기에서 AS번호관리) : ICANN(Internet adress 주소 block 관리)의 부서, 5개의 지역 인터넷 등록기관(RIR)에 ASN 배포 - 5개의 RIR에게 Internet adress 주소 block 나눠줘서 Internet adress 주소 block이 ISP나 각 기관별로 할당되는 것 총괄
- transit AS: 이 AS에 붙어있는 host가 아닌 다른 AS에 붙어있는 host들의 traffic들이 in&out(transit)
- Stub AS VS Transit AS
연결 구조 단일 AS와 연결 다수의 AS와 연결 트래픽 역할 자체 트래픽만 처리 외부 트래픽 전달 가능 주요 사용 사례 소규모 네트워크(기업, 학교) 대규모 ISP, 백본 네트워크 트래픽 전달 불가능 가능 - 인터넷: AS들의 집합
scalable routing에 대한 인터넷 접근방식
- intra-AS routing
- 호스트 간 라우팅, 동일한 AS("네트워크")의 라우터 간 라우팅
- AS의 모든 라우터(게이트웨이 라우터(주로 AS에서 edge에 위치. bolder router, AS끼리 연결-다른 AS와 연결되는 물리적 링크 갖고있음) 포함)은 동일한 AS내 라우팅 프로토콜(OSPF, RIP,...)을 실행해야 함
- 다른 라우터는 다른 AS내 라우팅 프로토콜을 실행할 수 있음.
- 각 AS내에서 routing 알고리즘(LS,DV) 활용 프로토콜 사용 - 하나의 administrative control 밑에 있음
- 다른 AS라 다른 Intra, AS 사용해도 연결된 수단 필요
- inter-AS routing
- 서로 다른 AS끼리의 연결 위해 만들어짐 - AS간 라우팅
- 이들이 다른 AS라서 다른 intra-AS routing 사용한다 해도 이들 간 연결 위해서는 공통된 routing protocal 사용해야 함.
- 게이트웨이 라우터는 도메인 내 라우팅뿐만 아니라 AS간 라우팅 프로토콜(BGP: 모든 AS들이 서로 interconnect되게 하기 위해서는 전세계적으로 공통적인 것 사용해야 )수행
- AS차원으로 라우팅- routing의 source & destination 차원이 specific subnet에 다려있는 host X. AS차원- gateway router 들만 참여
상호연결된 AS
- 내부 및 AS간 라우팅 알고리즘에 의해 구성된 포워딩테이블
- AS내 라우팅은 AS내 목적지에 대한 항목 결정.
- AS간 및 AS내 라우팅은 외부목적지에 대한 항목 결정

Intra-AS Routing
- 내부 게이트웨이 프로토콜(IGP)라고도 함 : 가장 일반적인 AS내 라우팅 프로토콜:
- RIP(routing information protocal): 내부 게이트웨이 프로토콜
- 클래식 DV: DV가 30초마다 교환
- 더이상 널리 사용되지 않음
- EIGRP(enhanced interior gateway routing protocal) : 향상된 내부 게이트웨이 라우팅 프로토콜
- DV 기반
- 이전에는 수십년간 cisco독점-개별적으로 소유한 라우팅 프로토콜(2013년 개방)
- OSPF(open shortest path first): 최단경로 우선개방, 현재 많이 사용
- IS-IS 프로토콜(RFC 표준이 아닌 ISO-표준화 목적으로 하는 단체-표준) : OSPF와 본질적으로 동일
- RIP(routing information protocal): 내부 게이트웨이 프로토콜
*classless : subnet prefix의 길이가 flexible
RIP

- 거리벡터 알고리즘
- 30초에 1번씩 나의 DV를 이웃에게 보냄(누락하지 X 반영할 수 있도록 아무런 변화가 없어도 생존신고)
- 일반적으로: 나와 인접한 링크의 cost나 이웃이 새로운 거리벡터 보냈을 때 나의 own 거리벡터를 새로계산
- metric=hop count(최대 15홉)-network diameter가 15 이내인 네트워크에서만 RIP적용가능, 각 링크의 비용은 1
- 홉 수가 15를 초과하는 경로는 연결 불가
- DV(일명 광고)는 30초마다 이웃과 교환됨
- 각 광고에는 최대 25개의 대상 서브넷(IP주소)이 포함.
- Route entry - RIP msg : 각 목적지 subnet별로 거기까지 가는데 distance 얼마인지 적어야 함
- hope count + 25 destination subnets = 커버가능한 네트워크 사이즈 고정
- RIP msg : 각 목적지 subnet별로 거기까지 가는데 거리 얼마인지 적어야 함 - route entry : RIPv2
OSPF routing
- 개방: 공개사용 가능
- 네트워크 계층의 프로토콜 -> TCP/UDP에 encapsulate되지는 x
- link state알고리즘(대표적 라우팅 알고리즘으로 사용)
- 각 라우터는 전체 AS의 다른 모든 라우터에 OSPF 링크상태 광고를 (TCP, UDP를 사요하지 않고 직접 IP통해) flooding함
- multiple link cost 비용 측정가능: 대역폭, 최소지연(RTT), 최대 처리량, 안정성 등 -RIP는 hopecount가 유일한 라우팅 측정
- routing cost가 여러개라면 datagram마다 사용하고자 하는 routing cost다르면? 디자인할 때 자체는 routing cost별로 routing table 별도로 줄 수 있음. - 실제로는 이렇게 거의 사용하지 않음. - AS별로 routing cost 관리할 수는 x
- AS의 모든 라우터는 동일한 전체 토폴로지 맵을 갖고 있음
- 결과적으로 OSPF 라우팅 사용하면 모든 라우터들이 동일한 full network 토폴로지 맵 그림
- Dijkstra의 알고리즘을 사용하여 경로(forwarding table) 계산
- 보안: 모든 OSPF msg 인증 -> 악의적 침입 방지
계층적 OSPF : 2단계 계층구조
- AS는 로컬영역, 하나의 backbone 영역으로 나뉨 - 통째로 다루지 x, 계층적으로 -> scale이 훨씬 큰 네트워크 커버가능
- link state 광고(LSA)는 영역 경계 라우터(ABR)에서만 flooding됨 - area 범위로 제한
- 백본(Backbone)은 컴퓨터 네트워크에서 데이터 통신을 위한 중심 역할을 하는 고속 네트워크 또는 네트워크 구성 요소

- ABR(area border routers): , 영역 경계 라우터, 자체 영역에서 목적지까지의 거리를 요약하고 백본에서 광고- 얘네끼리는 어떤 목적지 subnet으로 가려면 이 ABR로 보내야 하네? 알 수 있음
- ASBR(AS boundary router): AS 경계 라우터, ex. gateway router, bolder router)다른 AS(현재 AS system 외부)로 연결
- backbone router: 백본으로 제한된 OSPF 실행
- local or internal routers: area에서만 LS flood(area 내에 존재하는 subnet들에 대해), area 안에서 라우팅 계산, 영역 경계 라우터를 통해 외부로 패킷 전달(area 내의 목적지 subnet에 대해서는 area내에서 그 router 둘만 거쳐서 전달. area 바깥의 " -> backbone 사용
5.4 인터넷 서비스 제공업자(ISP) 간의 라우팅: BGP
Routing protocols in the Internet
Exterior(Inter-AS routing)
AS간 라우팅: 도메인 내 포워딩의 역할
- AS1의 라우터가 AS1 외부로 향하는 데이터그램 수신한다고가정
- 라우터는 패킷을 AS1의 게이트웨이 라우터로 전달해야 하지만 어느 라우터로 전달해야 할까?
- AS1 도메인 간 라우팅은 반드시 필요
- AS2를 통해 도달할 수 있는 목적지와 AS3을 통해 도달할 수 있는 목적지 파악
- 이 도달 가능성 정보를 AS1의 모든 라우터에 전파
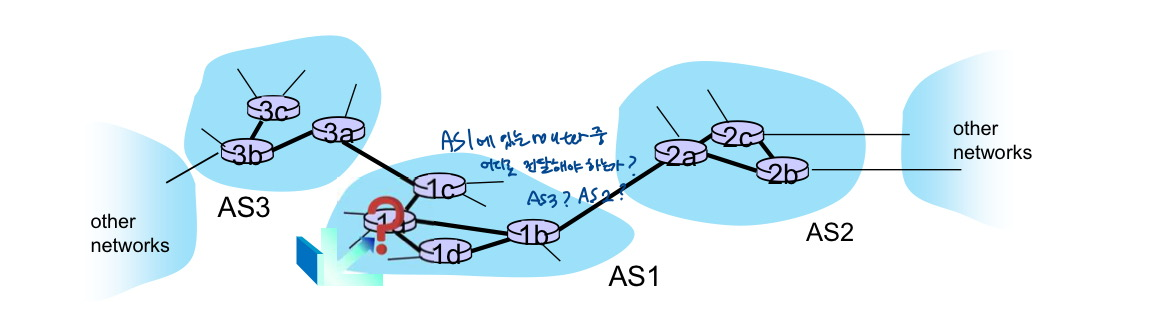
BGP(Border Gateway Protocol)
- 나 여기 있는데, 나를 통해서는 ~로 갈 수 있어. 거기로 가는 루트는 ~야.
- inter-AS routing : 인터넷을 하나로 묶어주는 접착제;
- 인터넷 백본에 널리 사용
- 서브넷이 자신의 존재와 도달할 수 있는 대상을 나머지 인터넷에 알릴 수 있도록 함(내가 여기 있고 누구에게 어떻게 연결할 수 있는지)
- BGP는 각 AS에 이를 위한 수단을 제공
- eBGP(배워오기): 인접한 AS로부터 서브넷 도달 가능성 정보 획득 - gateway router들이 배움 -> 나의 AS안에 소문을 다 퍼뜨려 줘야 함
- iBGP(퍼뜨리기): 도달 가능성 정보를 모든 AS 내부 라우터에 전파.
- BGP는 정책기반(경로벡터)라우팅을 제공, 기본목적: cost 최적화, vector 알고리즘의 일종, 목적지별로 거쳐가는 경로를 줌. -cost보다 policy가 우선
- 도달 가능성 정보 및 정책을 기반으로 다른 네트워크에 대한 좋은 경로 결정
- AS가 traffic 흐름을 제어할 수 있게 해줌
BGP: peering
- peering: 라우팅 정보 및 트래픽 교환
- 상업적으로: 비슷한 규모의 네트워크 간
- 무료
- BGP peers(이웃) : BGP msg를 교환하는 두 라우터
- eBGP(외부 BGP peering)간 서로 다른 AS간
- eBGP 피어는 서로 다른 ASNs를 가짐
- eBGP는 라우팅 정책을 구현
- 이들은 직접 연결돼야 함
- 동일한 AS내의 iBGP(내부 BGP 피어링)
- iBGP 피어는 동일한 ASN을 가짐
- 완전히 mesh(그물)화 되어야 함(반드시 직접 연결될 필요는 x)
- iBGP피어는 일반적으로 IGP를 사용하여 연결할 수 있어야 함
eBGP, iBGP 연결 _DGP 시즌은 2개의 BGP router간 이루어짐

와,,,,다날아감 저장도 다햇는데 미친거아냐?
182~191
BGP 기본 작업
BGP: inter-AS routing
BGP messages
BGP routes: path 속성
BGP Path 속성: AS_PATH 와 NEXT_HOP
BGP Path 속성: policy
BGP: adbertisements를 통해 정책 달성
BGP: route 선택
최적의 경로설정 - hot potato routing
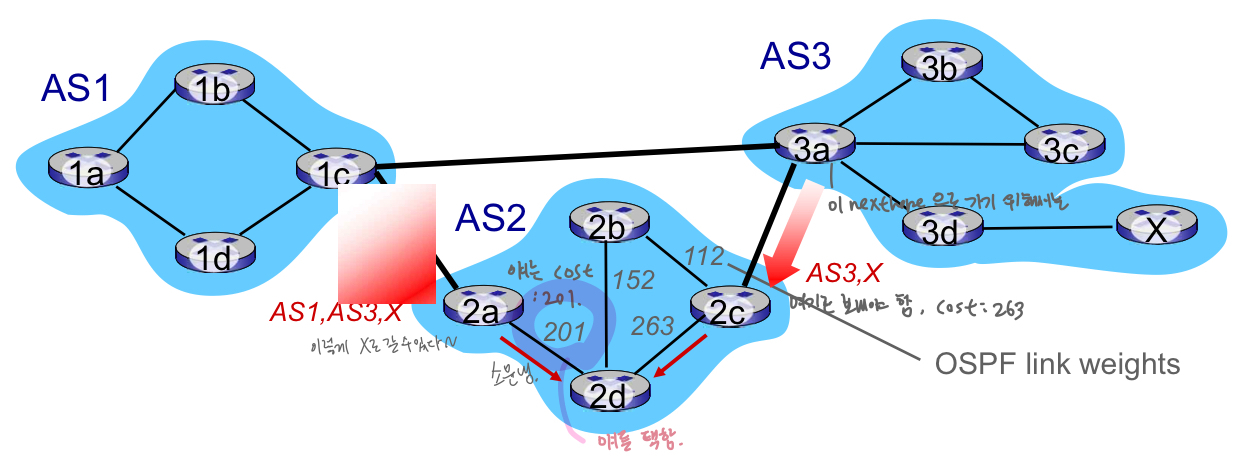
- 2d는 그것이 2a나 2c를 경유해 X로 route 할 수 있다는 것을 배움(via iBGP)
- 핫포테이토 라우팅 : 도메인 내 비용이 가장 적은 로컬 게이트웨이 선택
- 예: 2d는 X에 더 많은 AS홉이 있지만 2a를 선택
- 도메인 간 비용에 대해 걱정하지 마쇼!
BGP 경로광고 : 예시1
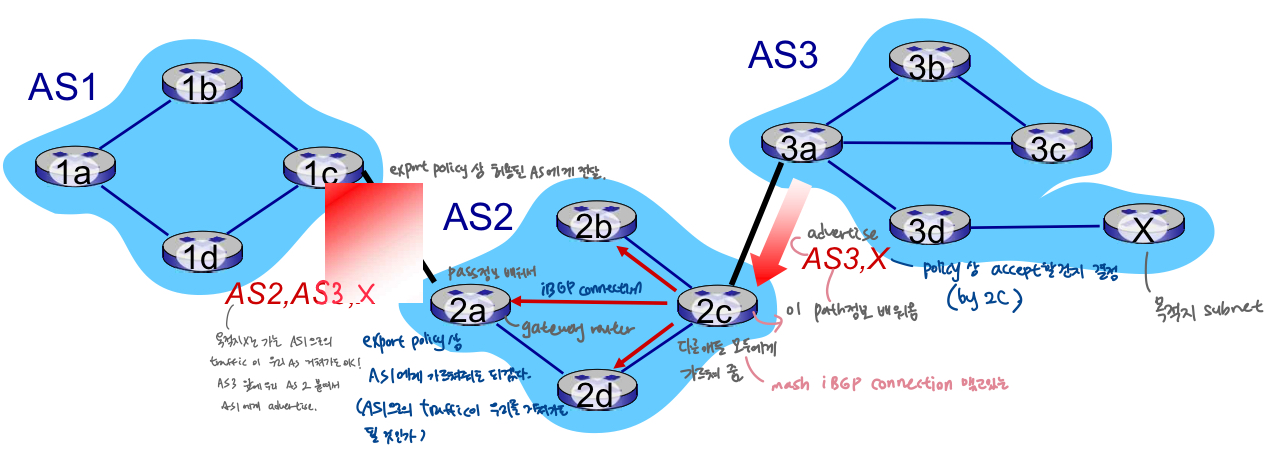
- AS2 라우터 2c는 AS3라우터 3a로부터 경로 AS3, X수신(eBGP를 통해)
- AS2정책에 따라 AS2라우터 2c는 경로 AS3, X 수락, 모든 라우터에게 전파(iBGP를 통해)
- AS2 정책에 따라 AS2라우터 2a가 경로 AS2, AS3, X를 AS1라우터 1c에 (eBGP를 통해)알림
BGP 경로광고 : 예시2

- 게이트웨이 라우터는 목적지로 가는 여러 경로를 학습할 수 있음
- AS1 게이트웨이 라우터 1c는 2a에서 경로 AS2, AS3, X 학습
- AS1 게이트웨이 라우터 1c는 3a(다음홉 라우터 됨)에서 경로 AS3, X를 학습
- 정책에 따라 AS1게이트웨이 라우터 1c가 경로 AS3, X를 선택하고 iBGP를 통해 AS1내 경로를 알림
정리하기: 항목이 라우터의 포워딩 테이블로 어떻게 전달되나요?

- 내부 및 AS간 라우팅 알고리즘에 의해 구성된 포워딩 테이블
- intra-AS는 internal 목적지에 대해 entries 세팅 - 얘만 이용해서 forwarding table entry setting
- inter-AS & intra-AS는 external 목적지에 대해 entries 세팅 - 우리 AS 바깥에 있는 애들, 정보 소문낸 router로 가기 위한 internal 경로 파악-> 그 next hope router을 forwarding table의 next hope router로 결정
예1: BGP, OSPF로 forwarding table 설정하기
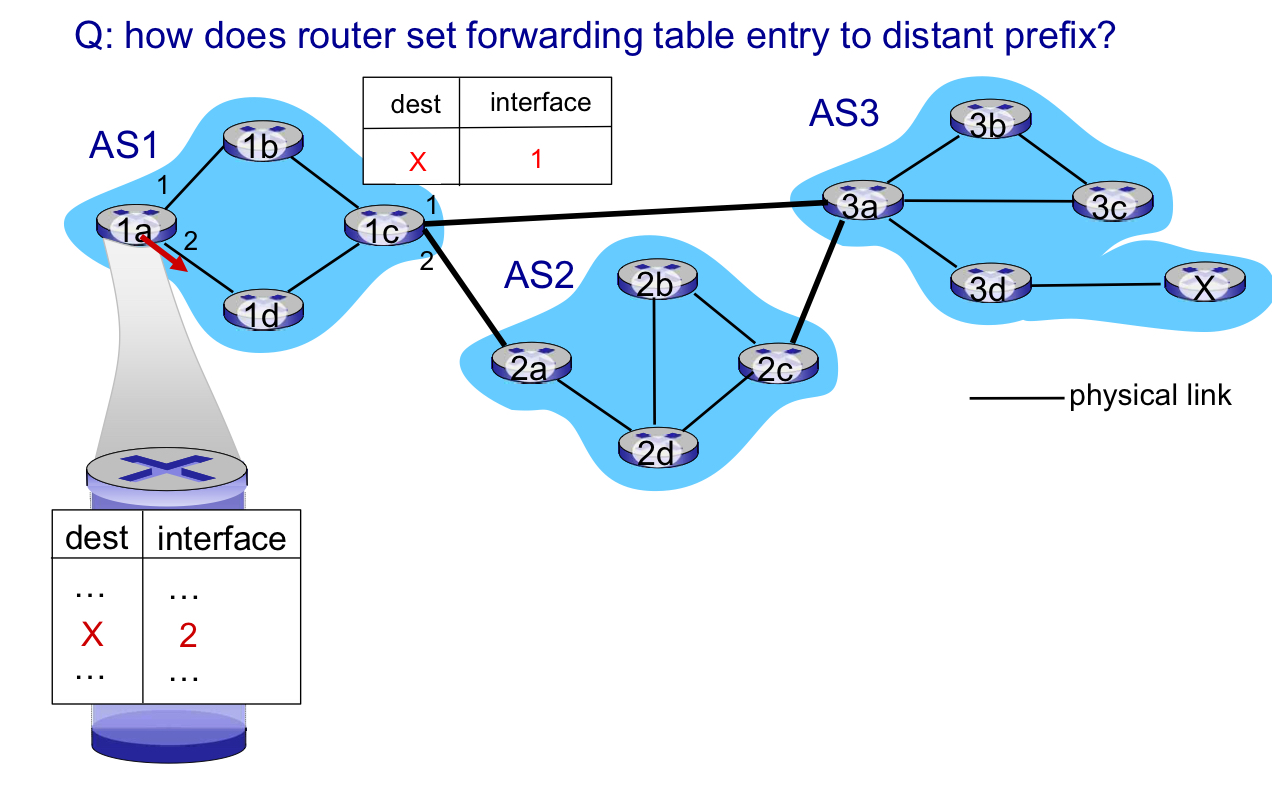
Q. 라우터는 어떻게 포워딩 테이블 항목을 먼 접두사로 설정하나?

- A.
- recall: 1a, 1b, 1d는 목적지 X에 대해 iBGP를 통해 1c로부터 배운다. : "X로 가는 경로는 1c를 통과한다."
- 1d: OSPF 도메인 내 라우팅: 1c로 가기 위해 outgoing local 인터페이스 1을 통해 포워드 전달
예2: BGP, OSPF로 forwarding table 설정하기
- AS1이 (AS간 프로토콜을 통해) AS2가 아닌 AS3(게이트웨이 1c)를 경유하여 서브넷 x에 닿을 수 있다는 것을 배웠다고 가정.
- inter-AS 프로토콜은 모든 내부 라우터에 도달 가능성을 전파
- 라우터1은 0이 1c에 대한 최소비용경로에 있는 경우 인터페이스를 통해 내부 AS라우팅정보에서 결정- 포워딩 테이블 항목(x, if0) 설치
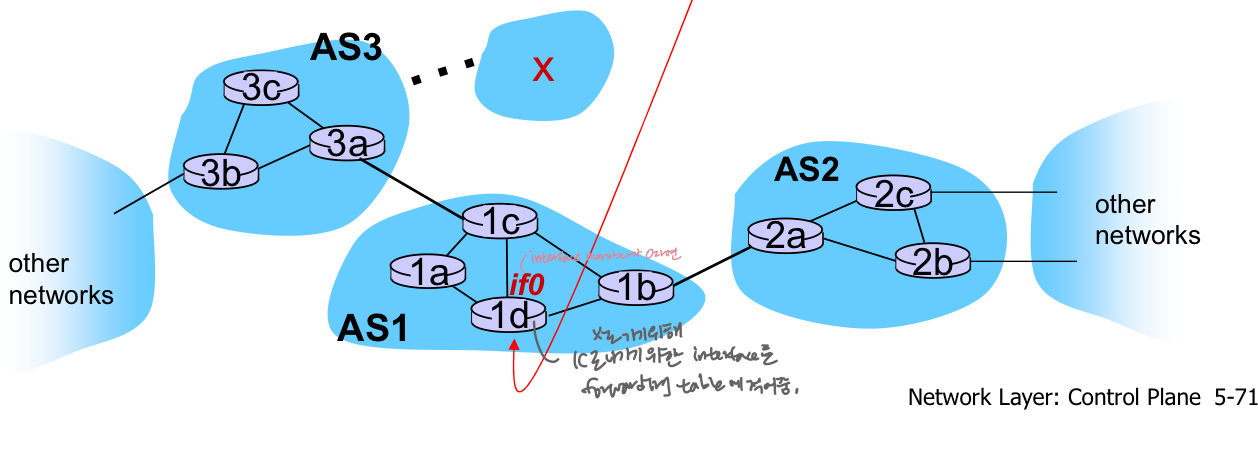
예3: BGP, OSPF로 forwarding table 설정하기

- 라우터가 접두사 인식
- BGP 메시지에 루트 포함
- 루트는 접두사 및 속성임: AS-PATH, NEXT-HOP...
- 라우터는 동일한 접두사에 대해 여러 경로 수신가능
- 하나의 경로를 선택해야 함
- 접두사로 사용할 최적의 BGP경로 선택
- policy -> AS-PATH-> NEXT-HOP->...
*자세한 prefix는 피피티에~
왜 다른 Intra-, Inter-AS 라우팅이 필요한가요?
- policy:
- inter-AS: 관리자가 트래픽 라우팅 방법과 라우팅 대상에 대한 제어를 원함
- 나를 transit하는 control이 어떤 것이 될 수 있는지는 컨트롤할 수 있어야 함
- intra-routing: 단일 관리자가 정책을 결정하므로 확장할 필요 x
- single domain -> 퍼포먼스가 중요(적은 resource 쓰여 빨리 연결이 중요)
- inter-AS: 관리자가 트래픽 라우팅 방법과 라우팅 대상에 대한 제어를 원함
- scale:
- 세상의 모든 라우터가 동일한 라우팅 프로토콜 쓴다면 자기에게 붙어있는 모든 subnet 리쳐빌리티 정보는 네트워크 전체에 flooding하던지 distance vector가 다 reply해서 나가던지 해야함
- 계층적 라우팅으로 테이블 크기 절약, 업데이트 트래픽 감소 - 계층적이지 않으면 라우팅테이블 증가, 업데이트 증가
- 성능
- intra -AS: 성능에 집중할 수 있음, performance가 중요
- inter-AS: 정책이 성능보다 우선할 수 있음, policy가 더 중요
문제풀이
Q. BGP(path vector. 루프문제 X)에서 경로의 루프를 어떻게 감지할 수 있는지 설명하시오.
- RIP에서는 라우팅 루프가 큰 문제였음
- split horizon with horizon reverse에 의해 routing 정보 주고받는 루프가 2개 라우터만 관여 -> split horizon과 horizon reserve에 의해 이 루프를 break up 할 수 있음 - 3개 이상의 라우터들이 이 라우팅 정보 주고받는 루프 형성 -> 그 방식으로 해결불가. 한동안 계속 settle되지 못한채 counting to infinity 문제
- A. AS에서 목적지까지 전체 AS경로 정보를 BGP에서 사용할 수 있으므로 루프감지는 간단하다.
- path information에 의해 단순히 nexthope만 나오는 게 x, 거치게 되는 AS list전체가 나옴
- 루프가 있다는 것 금방 발견 : recheability 정보 받았는데 거기 path attribute 봤더니 내가 이미 그 AS path list에 들어가 있음, 근데 또 받음 -> 루프 있다 ! (나로부터 나간 걸 나로부터 또 받음)
- path 속성 중 AS path list에 내 AS번호가 등장하는지 보고 금방 루프있는지 파악
Q. 아래 표시된 네트워크를 생각해봐라. AS3과 AS2가 AS내부 라우팅 프로토콜로 OSPF 실행하고 있다고 가정. AS1과 AS4가 AS내부 라우팅 프로토콜로 RIP 실행하고 있다고 가정, AS1과 AS4가 AS내부 라우팅 프로토콜로 RIP실행하고 있다고 가정. AS간 라우팅 프로토콜로 eBGP와 iBGP를 사용한다고 가정. 처음에는 AS2와 AS4 사이에 물리적 링크가 없다고 가정
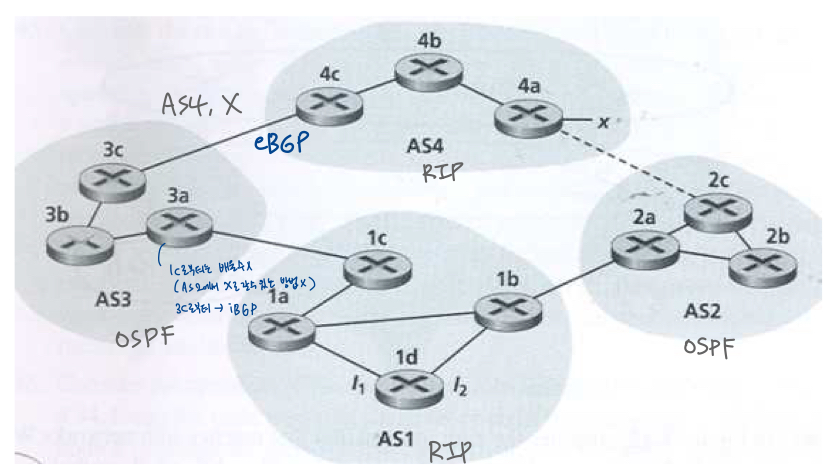
- 라우터 3c는 어떤 라우팅 프로토콜에서 접두사 x에 대해 학습하는가?: OSPF, RIP, eBGP, iBGP 중에서
- A. eBGP
- 라우터 3a는 어떤 라우팅 프로토콜에서 x에 대해 학습하는가?
- A. iBGP
- 라우터 1c(3a로부터 배워옴)는 어떤 라우팅 프로토콜에서 x에 대해 학습하는가?
- A. eBGP
- 라우터 1d는 어떤 라우팅 프로토콜에서 x에 대해 학습하는가?
- A. iBGP - 1c가 배워온걸 iBGP통해 알게됨
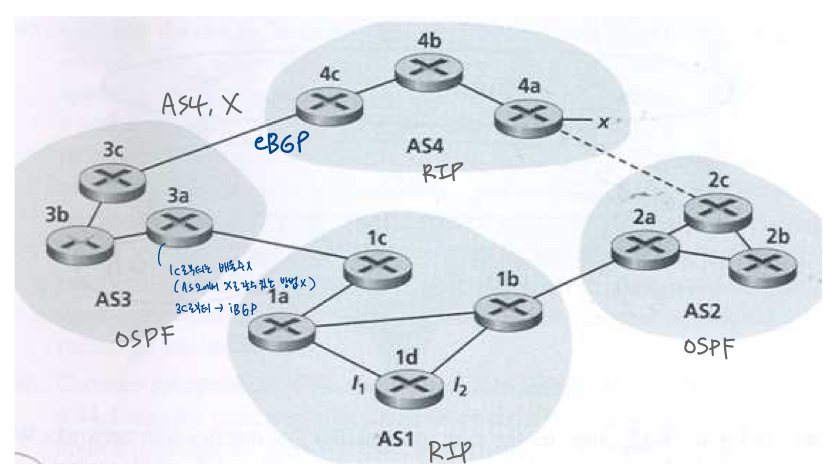
Q. 위 문제에서 라우터 1d가 x에 대해 알게 되면 포워딩 테이블에 (x,l)을 넣는다.
*x: 서브넷에 대해 배우면(리쳐빌리티 정보를 들으면) 자신의 forward table에다가 "x로 가기 위해서는 내 인터페이스 중 ~로 내보내면 된다." 세팅.
- 1d의 인터페이스를 l1, l2 둘 중 어느걸로 세팅할 것인가? 이유를 한 문장으로 설명해라.
- A. l1/ 왜냐하면 이 인터페이스는 1d에서 gateway router 1c로 향하는, 가장 비용이 적게 드는 경로로 시작하기 때문이다.
- 이제 AS2와 AS4사이에 점선으로 표시된 물리적 링크가 있다고 가정하자. (점선->실선) 라우터 1d가 AS3뿐만 아니라 AS2를 통해서도 x에 액세스할 수 있게 되었다고 가정하자. l이 l1, l2 둘 중 어느걸로 세팅할 것인가? 이유를 한 문장으로 설명해라.
- l2/ 두 경로의 AS-path 길이는 같지만(AS번호의 개수로 판단. 개별 라우터개수 상관X) 가장 가까운 NEXT-HOP router가 있는 경로에서 l2가 시작.
- x라는 서브넷에 대해 1c도, 1d도 소문냄(AS3, AS4 통해 X로 갈 수 있음/ AS2통해 X로 갈 수 있음)
- 둘 다 AS path 길이 2. hot potato 적용하면 나에게서 더 가까운 애는 1b -> 인터페이스 2로 내보냄
- l2/ 두 경로의 AS-path 길이는 같지만(AS번호의 개수로 판단. 개별 라우터개수 상관X) 가장 가까운 NEXT-HOP router가 있는 경로에서 l2가 시작.
- 이제 AS2와 AS4 사이의 경로에 AS5라는 또 다른 AS가 있다고 가정하자.(다이어그램에 표시되지 않음). 라우터 1d가 AS2, AS5, AS4와 AS3, AS4를 통해 x에 액세스할 수 있다는 것을 알게 되었다고 가정하자. l1 or l2 무엇으로 세팅될것인가? 이유를 한 문장으로 설명해라.
- l1/ l1은 AS-PATH가 가장 짧은 경로로 시작.
'CS > 컴퓨터네트워크' 카테고리의 다른 글
| [컴퓨터네트워크] chap6 Link Layer + 총정리 (4) | 2024.12.10 |
|---|---|
| [컴퓨터 네트워크] chap 5. Network layer (5.5 | 5.6 | 5.7) (1) | 2024.12.09 |
| [컴퓨터 네트워크] chap4. Network Layer : The Data Plane ( 4.3 | 4.4 | 4.5) (1) | 2024.12.01 |
| [컴퓨터 네트워크] chap4. Network Layer : The Data Plane ( 4.1 | 4.2 ) (1) | 2024.11.22 |
| [컴퓨터 네트워크] chap3. Transport Layer (1) | 2024.10.22 |