9.1 우선순위 큐 추상 데이터 타입
[우선순위 큐]
- 데이터들이 우선순위 갖고있고 우선순위 높은 데이터가 먼저 나간다.
- 0개 이상의 요소 모임(각 요소는 우선순위값 갖고 있음)
- 최소 우선순위 큐: 가장 우선순위 낮은 요소가 먼저 삭제
- 최대 우선순위 큐: 가장 우선순위 높은 요소가 먼저 삭제

9.2 우선순위 큐의 구현방법
1. 배열 사용
- 정렬 안 된 배열 사용:
- 삽입 - 배열의 맨 끝에 새로운 요소 추가> 시간복잡도 O(1)
- 삭제 - 가장 우선순위가 높은 요소를 찾아야 한다. > 정렬 안 돼 있으므로 처음부터 끝까지 모든요소 스캔 > 시간복잡도 O(n)+요소 삭제된 다음 뒤에 있는 요소를 앞으로 이동시켜야 한다.
- 정렬된 배열 사용:
- 삽입- 위치 찾기 위해 순차탐색, 이진탐색 이용> 삽입위치 뒤의 요소 이동시켜서 빈자리 만들고 삽입> 시간복잡도: O(n)
- 삭제- 순서가 높은 것이 우선순위 높다고 가정> 맨 뒤 위치한 요소 삭제> 시간복잡도: O(1)
2. 연결리스트 사용
- 정렬 안 된 연결리스트:
- 삽입- 첫 번째 노드로 삽입하되 다른 노드 이용할 필요 없고 포인터만 변경 > 시간복잡도: O(1)
- 삭제- 포인터 따라서 모든 노드 뒤지기 > 시간복잡도: O(n)
- 정렬 된 연결리스트:
- 삽입 - 우선순위 높은 요소가 첫 번째 노드가 되도록 하고 우선순위값을 기준으로 삽입위치 찾아야 한다. > 시간복잡도: O(n)
- 삭제 - 첫 번째 노드 삭제 > O(1)

9.3 히프
[히프(heap)]
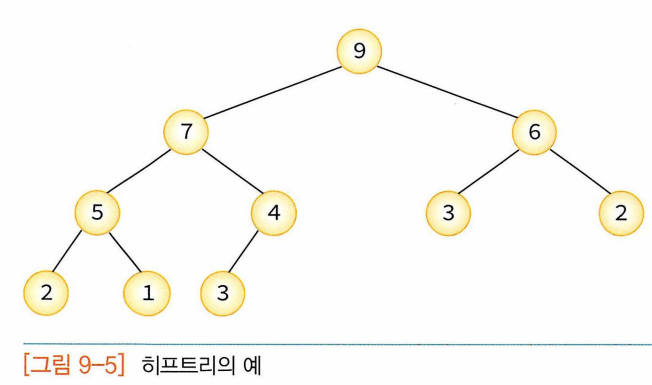
- 완전 이진트리의 일종
- heap=더미
- 저장하는 표준적 자료구조: 배열
- 우선순위 큐를 위해 특별히 만들어졌다.
- 느슨한 정렬 상태 유지
- 여러 개 값 중 가장 큰 값이나 가장 작은 값을 빠르게 찾아내도록 만들어졌다.
- 부모노드와 자식노드간 "key(부모노드) >= key(자식노드)" 가 항상 성립
- 중복된 값 허용
- 최대히프(부모노드 키값이 자식노드 키값보다 큼) , 반대인 최소히프 두 종류. 최대히프만을 다룰것임.
[히프의 구현]
-완전이진트리이기에 차례대로 번호 붙일 수 O. 이 번호를 배열의 인덱스로 생각하면 배열에 히프 노드 저장 가능하다. (배열 첫번째 인덱스인 0 사용 x. 특정위치 노드번호는 새로운 노드 추가돼도 변하지 않음
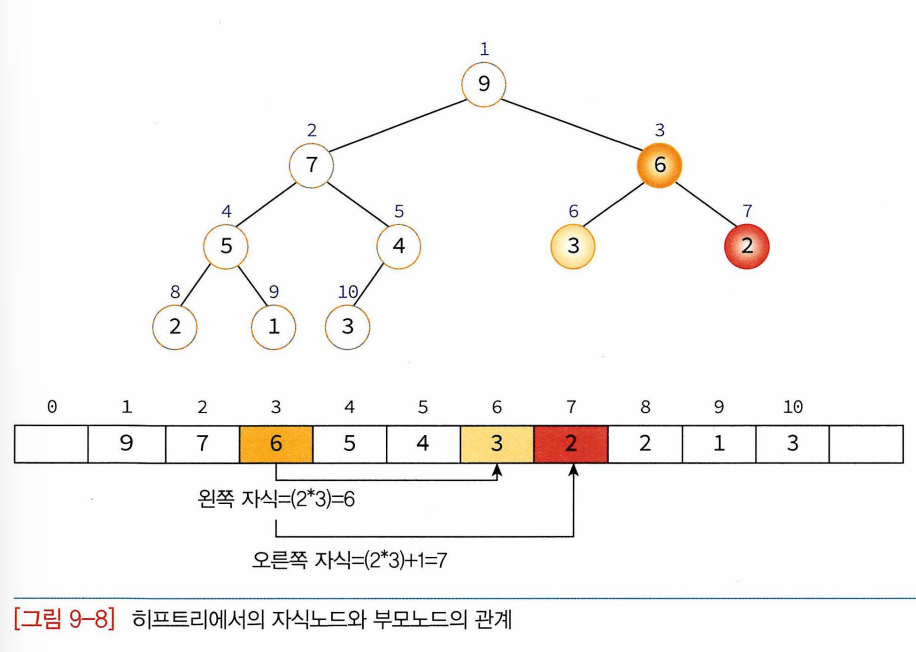
- 왼쪽 자식의 인덱스= (부모 인덱스) * 2
- 오른쪽 자식의 인덱스= (부모 인덱스)*2+1
- 부모의 인덱스= (자식 인덱스)/2
9.4 히프의 구현
-1차원 배열로 표현 가능> 히프의 각 요소들을 구조체 element로 정의> element의 1차원 배열 만들어 히프 구현
- 삽입연산 : 신입사원 말단 자리에 앉히고 승진시키는 것과 비슷. 새로운 요소가 들어오면 히프의 마지막 노드에 삽입한다. 마지막 노드 다음에 새로운 노드 위치시키면 히프트리 성질이 만족되지 않을 수 있기 때문에 새로운 노드를 부모 노드들과 교환해서 히프 성질 만족시켜야 한다. (성질 만족할 때까지 위로 올라가면서 교환)
- 삭제연산 : 사장의 자리가 빌 때 제일 먼저 말단사원 사장자리로 올리고 강등시키는 것과 비슷. 최대히프에서 삭제연산은 최대값을 가진 요소 삭제하는 것(루트노드 삭제) >> 히프의 재구성 필요(히프 성질 만족을 위해 위 아래 노드 교환)
[복잡도 분석]
- 삽입/ 삭제: 새로운 요소가 올라가며/내려가며 부모노드/자식노드들과 교환, 최악의 경우 루트노드까지 올라가야 함> 트리의 높이에 해당하는 비교연산 및 이동연산 필요.

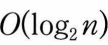
히프의 높이 (히프가 완전이진트리이므로)
삽입의 시간복잡도
9.5 히프정렬
-최대히프 이용하면 정렬 가능
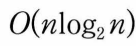
시간 안에 정렬. 히프 사용하는 정렬 알고리즘: 히프 정렬(heap sort)
[복잡도]
하나의 요소를 히프에 삽입하거나 삭제할 때 히프 재정비하는 시간 (히프가 완전이진트리이므로)

전체적으로 걸리는 시간_시간복잡도(요소의 개수가 n개이므로) -->삽입정렬이 O(n^2)걸리는 것에 비하면 좋은 편, 전체 자료 정렬 x 가장 큰 값 몇 개만 필요할 때 최대 유용
9.6 머쉰 스케줄링
: 동일한 기계 m개, 처리해야 하는 작업 n개일 때 각 작업이 필요로 하는 기계 사용시간 다름> 모든 기계 풀가동하여 가장 최소의 시간 안에 작업 모두 끝내는 것
-LPT(longest processing time first): 가장 긴 작업을 우선적으로 기계에 할당, 최소히프 사용
9.7 허프만 코드
-허프만 코딩 트리: 각 글자 빈도가 알려져 있는 메시지 내용 압축에 사용되는 이진트리
ㄴ빈도수 이용하여 데이터 압축할 때 각 글자 나타내는 최소길이 엔코딩 비트열 만들 수 있다. (전체 데이터 양 줄이기 위해 가변 길이 코드 사용> 가장 많이 등장하는 글자에는 짧은 비트열 사용, 잘 나오지 않는 글자에는 긴 비트열 사용)
ㄴ해독: 코드 관찰해보면 모든 코드가 다른 코드의 첫부분이 아님> 코딩된 비트열을 왼쪽에서 오른쪽으로 조사해보면 정확히 하나의 코드만 일치한다!! 이러한 특수 코드 만들기 위해 이진트리 사용
[허프만 코드 만드는 절차]
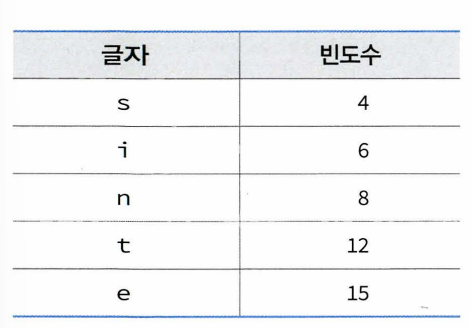

- 빈도수에 따라 5개의 글자를 나열하고 가장 작은 빈도수 가지는 글자 2개 추출> 이들을 단말노드로 하여 이진트리 구성. 루트의 값 = 각 자식노드 합한 값

- 정렬된 글자들의 리스트로 돌아가서 합쳐진 값 리스트에 삽입 > 정렬해서 (8, 10, 12, 15) 얻음 > 다시 가장 작은 값 2개 단말노드로 하여 이진트리 구성
- 정렬된 리스트로 돌아가서 이 합쳐진 값 리스트에 삽입 > 정렬해서 (12, 15, 18) 얻음> 다시 이중에서 가장 작은 값 2개를 단말노드로 하여 이진트리 구성

- 같은 방식으로 (18,27) 구하고 이 두 값을 단말노드로 하여 이진트리 구성
*왼쪽간선은 비트 1, 오른쪽 간선은 비트 0 나타냄
'CS > 자료구조' 카테고리의 다른 글
| [자료구조] chap11. 그래프 II (1) | 2024.11.12 |
|---|---|
| [자료구조] chap10. 그래프 I (4) | 2024.11.05 |
| [자료구조] chap8. 트리 (0) | 2024.10.22 |
| [자료구조] chap7. 연결리스트 II (0) | 2024.10.21 |
| [자료구조] chap6. 연결리스트 I (1) | 2024.10.18 |